142. Linux
概述
Linux 简介
Linux 内核最初只是由芬兰人林纳斯·托瓦兹(Linus Torvalds)在赫尔辛基大学上学时出于个人爱好而编写的。
Linux 是一套免费使用和自由传播的类 Unix 操作系统,是一个基于 POSIX(可移植操作系统接口) 和 UNIX 的多用户、多任务、支持多线程和多 CPU 的操作系统。
Linux 能运行主要的 UNIX 工具软件、应用程序和网络协议。它支持 32 位和 64 位硬件。Linux 继承了 Unix 以网络为核心的设计思想,是一个性能稳定的多用户网络操作系统。
Linux 发行版
Linux 的发行版说简单点就是将 Linux 内核与应用软件做一个打包。

目前市面上较知名的发行版有:Ubuntu、RedHat、CentOS、Debian、Fedora、SuSE、OpenSUSE、Arch Linux、SolusOS、kali(安全渗透测试使用) 等。

今天各种场合都有使用各种 Linux 发行版,从嵌入式设备到超级计算机,并且在服务器领域确定了地位,通常服务器使用 LAMP(Linux + Apache + MySQL + PHP)或 LNMP(Linux + Nginx+ MySQL + PHP)组合。
目前 Linux 不仅在家庭与企业中使用,并且在政府中也很受欢迎。
- 巴西联邦政府由于支持
Linux而世界闻名。 - 有新闻报道俄罗斯军队自己制造的
Linux发布版的,做为G.H.ost项目已经取得成果。 - 印度的
Kerala联邦计划在向全联邦的高中推广使用Linux。 - 中华人民共和国为取得技术独立,在龙芯处理器中排他性地使用
Linux。 - 在西班牙的一些地区开发了自己的 Linux 发布版,并且在政府与教育领域广泛使用,如
Extremadura地区的gnuLinEx和 Andalusia 地区的Guadalinex。 - 葡萄牙同样使用自己的 Linux 发布版
Caixa Mágica,用于Magalh?es笔记本电脑和e-escola政府软件。 - 法国和德国同样开始逐步采用
Linux。
Linux vs Windows

环境搭建
Linux 的安装,安装步骤比较繁琐(操作系统本身也是一个软件),现在其实云服务器挺普遍的,价格也便宜,如果直接不想搭建,也可以直接买一台学习用用!
安装CentOS(不推荐)
虚拟机安装,耗资源,在本地安装,这个不建议;
Linux 是一个操作系统,你也可以把自己电脑安装成双系统!建议使用虚拟机(VM)
可以使用已经制作好的镜像!
CentOS7网盘地址:链接,提取码:76x5,登录密码:123456装
VMware虚拟机软件,然后打开镜像即可使用!安装完成后,有如下界面:

VMware使用方式- 点击屏幕进入虚拟机;
ctrl+alt将聚焦退出虚拟机;

购买云服务器(推荐)
虚拟机安装后占用空间,也会有些卡顿,我们作为程序员其实可以选择购买一台自己的服务器,这样的话更加接近真实线上工作;
阿里云购买服务器:点击这里
购买完毕后,获取服务器的ip地址,重置服务器密码,就可以远程登录了
下载
xShell工具,进行远程连接使用!连接成功效果如下:

注意事项
如果要打开端口,需要在阿里云的安全组面板中开启对应的出入规则,不然的话会被阿里拦截!
新手
如果前期不好操作,可以推荐安装宝塔面板,傻瓜式管理服务器
安装教程:点击这里
开启对应的端口
一键安装
安装完毕后会得到远程面板的地址,账号,密码,就可以登录了
登录之后就可以可视化的安装环境和部署网站!


走近Linux系统
开机登录
开机会启动许多程序。它们在Windows叫做”服务“(service),在Linux就叫做”守护进程“(daemon)。
开机成功后,它会显示一个文本登录界面,这个界面就是我们经常看到的登录界面,在这个登录界面中会提示用户输入用户名,而用户输入的用户将作为参数传给login程序来验证用户的身份,密码是不显示的,输完回车即可!
一般来说,用户的登录方式有三种:
- 命令行登录
ssh登录- 图形界面登录
最高权限账户为 root,可以操作一切!
关机
在linux领域内大多用在服务器上,很少遇到关机的操作。毕竟服务器上跑一个服务是永无止境的,除非特殊情况下,不得已才会关机。
关机指令为:shutdown ;
1 | sync # 将数据由内存同步到硬盘中。 |
最后总结一下,不管是重启系统还是关闭系统,首先要运行 sync 命令,把内存中的数据写到磁盘中。
系统目录结构
登录系统后,在当前命令窗口下输入命令:
1 | ls / |
你会看到如下图所示:

树状目录结构:(Linux的一切资源都挂载在这个 / 根节点下)

| 目录 | 说明 | 备注 |
|---|---|---|
/bin |
bin是Binary的缩写, 这个目录存放着最经常使用的命令。 |
不要动 |
/boot |
这里存放的是启动Linux时使用的一些核心文件,包括一些连接文件以及镜像文件。 |
不要动 |
/dev |
dev是Device(设备)的缩写, 存放的是Linux的外部设备,在Linux中访问设备的方式和访问文件的方式是相同的。 |
挂载第三方设备 |
/etc |
这个目录用来存放所有的系统管理所需要的配置文件和子目录。 | |
/home |
用户的主目录,在Linux中,每个用户都有一个自己的目录,一般该目录名是以用户的账号命名的。 |
|
/lib |
这个目录里存放着系统最基本的动态连接共享库,其作用类似于Windows里的DLL文件。 |
不要动 |
/lost+found |
这个目录一般情况下是空的,当系统非法关机后,这里就存放了一些文件。 | 存放突然关机的一些文件 |
/media |
linux系统会自动识别一些设备,例如U盘、光驱等等,当识别后,Linux会把识别的设备挂载到这个目录下。 |
|
/mnt |
系统提供该目录是为了让用户临时挂载别的文件系统的,我们可以将光驱挂载在/mnt/上,然后进入该目录就可以查看光驱里的内容了。 |
挂载第三方设备,我们一般会把一些本地文件挂载在这个目录下 |
/opt |
这是给主机额外安装软件所摆放的目录。比如你安装一个ORACLE数据库则就可以放到这个目录下。默认是空的。 | |
/proc |
这个目录是一个虚拟的目录,它是系统内存的映射,我们可以通过直接访问这个目录来获取系统信息。 | 不用管 |
/root |
该目录为系统管理员,也称作超级权限者的用户主目录。 | |
/sbin |
s就是Super User的意思,这里存放的是系统管理员使用的系统管理程序。 |
|
/srv |
该目录存放一些服务启动之后需要提取的数据。 | |
/sys |
这是linux2.6内核的一个很大的变化。该目录下安装了2.6内核中新出现的一个文件系统 sysfs 。 |
|
/tmp |
这个目录是用来存放一些临时文件的。 | 用完即丢的文件,可以放在这个目录下,如:安装包 |
/usr |
这是一个非常重要的目录,用户的很多应用程序和文件都放在这个目录下,类似于windows下的program files目录。 |
|
/usr/bin |
系统用户使用的应用程序。 | |
/usr/sbin |
超级用户使用的比较高级的管理程序和系统守护程序。 | |
/usr/src |
内核源代码默认的放置目录。 | |
/var |
这个目录中存放着在不断扩充着的东西,我们习惯将那些经常被修改的目录放在这个目录下。包括各种日志文件。 | |
/run |
是一个临时文件系统,存储系统启动以来的信息。当系统重启时,这个目录下的文件应该被删掉或清除。 | |
/www |
存放服务器网站相关的资源,如:环境、网站项目等; |
补充
- 很多的大型项目都是部署在
Linux服务器上; - 社会的生存法则:优胜劣汰;
- 服务器都是使用命令行的,我们也是基于命令行来学习的;
Linux中没有错误就代表操作成功;- 一切皆文件;
- 根目录:
/,所有的文件都挂载在这个节点下;
目录解释
/mnt: 后面会把一些本地文件挂载在这个目录下/etc:配置文件:/home:lost+found:存放 突然关机的一些文件/opt:安装额外的软件/root:/tmp:用完即丢
常用的基本命令
目录管理
- 绝对路径:路径的全称,如:
D:\anaconda3\condabin\xxx.xxx - 相对路径:比如说在
condabin目录下,那这个xxx.xxx文件,对应我们的相对位置就是./xxx.xxx
cd:切换目录命令
cd 目录名:绝对路径:都是以/开头;相对路径:对于当前目录该如何寻找../或./
./:当前目录cd ..:返回上一级目录

ls:列出目录(常常被使用)
参数:
-a参数:all,查看全部文件,包括隐藏文件-l参数:列出所有文件,包含文件的属性和权限,没有隐藏文件
实践:

pwd:显示当前用户所在的目录

mkdir:创建一个目录

rmdir:删除目录

rmdir仅能删除空的目录,如果下面存在文件,需要先删除文件;递归删除多个目录加入-p参数即可
cp:复制文件或者目录
cp 原来的文件 目标目录或者目标目录/要改成的文件名

rm:移除文件或者目录!
参数:
-f:忽略不存在的文件,不会出现警告,强制删除;-r:递归删除目录;-i:互动,删除询问是否删除;
实践:
rm -rf /:系统中所有的文件就被删除了(删库跑路)

mv:移动文件或者目录;重命名文件
参数:
-f:强制-u:只替换已经更新过的文件
实践:

基本属性
文件属性
root > user
Linux系统是一种典型的多用户系统,不同的用户处于不同的地位,拥有不同的权限。为了保护系统的安全性,Linux系统对不同的用户访问同一文件(包括目录文件)的权限做了不同的规定。
在Linux中我们可以使用ll或者ls –l命令来显示一个文件的属性以及文件所属的用户和组,如:

实例中,boot文件的第一个属性用”d“表示。”d“在Linux中代表该文件是一个目录文件。
在Linux中第一个字符代表这个文件是目录、文件或链接文件等等:
- 当为[
d]则是目录 - 当为[
-]则是文件; - 若是[
l]则表示为链接文档 (link file)(类似于window的快捷方式); - 若是[
b]则表示为装置文件里面的可供储存的接口设备 ( 可随机存取装置 ); - 若是[
c]则表示为装置文件里面的串行端口设备,例如键盘、鼠标 ( 一次性读取装置 )。
接下来的字符中,以三个为一组,且均为『rwx』 的三个参数的组合。
其中,[ r ]代表可读(read)、[ w ]代表可写(write)、[ x ]代表可执行(execute)。
要注意的是,这三个权限的位置不会改变,如果没有权限,就会出现减号[ - ]而已。
每个文件的属性由左边第一部分的10个字符来确定(如下图):

从左至右用0-9这些数字来表示。
第0位确定文件类型,第1-3位确定属主(该文件的所有者)拥有该文件的权限。第4-6位确定属组(所有者的同组用户)拥有该文件的权限,第7-9位确定其他用户拥有该文件的权限。
其中:
第1、4、7位表示读权限,如果用”r“字符表示,则有读权限,如果用”-“字符表示,则没有读权限;
第2、5、8位表示写权限,如果用”w“字符表示,则有写权限,如果用”-“字符表示没有写权限;
第3、6、9位表示可执行权限,如果用”x“字符表示,则有执行权限,如果用”-“字符表示,则没有执行权限。
对于文件来说,它都有一个特定的所有者,也就是对该文件具有所有权的用户。
同时,在Linux系统中,用户是按组分类的,一个用户属于一个或多个组。
文件所有者以外的用户又可以分为文件所有者的同组用户和其他用户。
因此,Linux系统按文件所有者、文件所有者同组用户和其他用户来规定了不同的文件访问权限。
在以上实例中,boot 文件是一个目录文件,属主和属组都为 root。
个人理解
属主:这个文件/目录属于那个用户的
属组:这个文件/目录属于哪个组的(属主不一定在这个组内)
修改文件属性
chgrp
更改文件属组
1 | chgrp [-R] 属组名 文件名 |
-R:递归更改文件属组,就是在更改某个目录文件的属组时,如果加上-R的参数,那么该目录下的所有文件的属组都会更改。

chown
更改文件属主,也可以同时更改文件属组
1 | chown [–R] 属主名 文件名 |

chmod(必须要掌握)
更改文件9个属性
遇到:“你没有权限操作此文件!”,就要使用
chmod
1 | chmod [-R] xyz 文件或目录 |
Linux文件属性有两种设置方法,一种是数字(常用的是数字),一种是符号。
Linux文件的基本权限就有九个,分别是owner/group/others三种身份各有自己的read/write/execute权限。
先复习一下刚刚上面提到的数据:文件的权限字符为:『-rwxrwxrwx』, 这九个权限是三个三个一组的!其中,我们可以使用数字来代表各个权限,各权限的分数对照表如下:
1 | r:4 w:2 x:1 |
每种身份(owner/group/others)各自的三个权限(r/w/x)分数是需要累加的,例如当权限为:[-rwxrwx---] 分数则是:
owner = rwx = 4+2+1 = 7group = rwx = 4+2+1 = 7others= --- = 0+0+0 = 0
1 | chmod 770 filename |
实例
| 权限 | 命令 | 对应数字 | 命令 |
|---|---|---|---|
| 可读可写不可执行 | rw- |
6 | |
| 可读可写可执行 | rwx |
7 | |
| 文件赋予所有用户可读可写可执行权限! | rwxrwxrwx |
777 | chmod 777 filename |

内容查看
概述
Linux系统中使用以下命令来查看文件的内容:
| 命令 | 说明 | 备注 | 示例 |
|---|---|---|---|
cat |
由第一行开始显示文件内容 | 用来读文章,或者读取配置文件,都使用 cat 命令 |
|
tac |
从最后一行开始显示,可以看出 tac 是 cat 的倒着写! |
 |
|
nl |
显示的时候,顺道输出行号! |  |
|
more |
一页一页的显示文件内容,带余下内容的 | 空格:翻页;enter:向下看一行;:f 显示行号 |
 |
less |
与 more 类似,但是比 more 更好的是,他可以往前翻页! |
空格:翻页;上下键:滚动行;pageDown, pageUp:翻动页面;q:退出;/字符串:向下查询字符串;?字符串:向上查询字符串;n/N:向下/向上查找下一个 |
 |
head |
只看头几行 | 通过 -n 参数来控制显示几行 |
 |
tail |
只看尾巴几行 | 同 head |
 |
你可以使用 *man [命令]*来查看各个命令的使用文档,如 :man cp。
网络配置目录:
/etc/sysconfig/network-scripts/默认网络配置文件:

查看网络配置:
win:ipconfiglinux:ifconfig

cat
由第一行开始显示文件内容
语法:
1 | cat [-AbEnTv] |
选项与参数:
-A:相当於-vET的整合选项,可列出一些特殊字符而不是空白而已;-b:列出行号,仅针对非空白行做行号显示,空白行不标行号!-E:将结尾的断行字节$显示出来;-n:列印出行号,连同空白行也会有行号,与-b的选项不同;-T:将[tab]按键以^I显示出来;-v:列出一些看不出来的特殊字符
测试:
1 | # 查看网络配置: 文件地址 /etc/sysconfig/network-scripts/ |
tac
tac与cat命令刚好相反,文件内容从最后一行开始显示,可以看出 tac 是 cat 的倒着写!如:
1 | [root@qeuroal ~]# tac /etc/sysconfig/network-scripts/ifcfg-eth0 |
nl
显示行号
语法:
1 | nl [-bnw] 文件 |
选项与参数:
-b:指定行号指定的方式,主要有两种:-b a:表示不论是否为空行,也同样列出行号(类似cat -n);-b t:如果有空行,空的那一行不要列出行号(默认值);-n:列出行号表示的方法,主要有三种:-n ln:行号在荧幕的最左方显示;-n rn:行号在自己栏位的最右方显示,且不加0;-n rz:行号在自己栏位的最右方显示,且加0;-w:行号栏位的占用的位数。
测试:
1 | [root@qeuroal ~]# nl /etc/sysconfig/network-scripts/ifcfg-eth0 |
more
一页一页翻动
在 more 这个程序的运行过程中,你有几个按键可以按的:
空白键 (space):代表向下翻一页;Enter:代表向下翻『一行』;/字串:代表在这个显示的内容当中,向下搜寻『字串』这个关键字;:f:立刻显示出档名以及目前显示的行数;q:代表立刻离开 more ,不再显示该文件内容。b或[ctrl]-b:代表往回翻页,不过这动作只对文件有用,对管线无用。
1 | [root@qeuroal etc]# more /etc/csh.login |
less
一页一页翻动,以下实例输出
/etc/man.config文件的内容:
less运行时可以输入的命令有:
空白键:向下翻动一页;[pagedown]:向下翻动一页;[pageup]:向上翻动一页;/字串:向下搜寻『字串』的功能;?字串:向上搜寻『字串』的功能;n:重复前一个搜寻 (与/或?有关!)N:反向的重复前一个搜寻 (与/或?有关!)q:离开less这个程序;
1 | [root@qeuroal etc]# more /etc/csh.login |
head
取出文件前面几行
语法:
1 | head [-n number] 文件 |
选项与参数:**-n** 后面接数字,代表显示几行的意思!
默认的情况中,显示前面 10 行!若要显示前 20 行,就得要这样:
1 | [root@qeuroal etc]# head -n 20 /etc/csh.login |
tail
取出文件后面几行
语法:
1 | tail [-n number] 文件 |
选项与参数:
-n:后面接数字,代表显示几行的意思
默认的情况中,显示最后 10 行!若要显示最后 20 行,就得要这样:
1 | [root@qeuroal etc]# tail -n 20 /etc/csh.login |
拓展:Linux 链接概念(了解即可)
Linux 链接分两种:
- 硬链接(
Hard Link):A------B:假设B是A的硬链接,那么他们两个指向了同一个文件,允许一个文件拥有多个路径,用户可以通过这种机制建立硬链接到一些重要文件上,防止误删! - 符合链接(
Symbolic Link)或叫软链接:类似windows下的快捷方式,即删除了源文件,快捷方式也访问不了。
命令
ln命令产生硬链接;touch创建文件;echo输入字符串,也可以输入到文件中;
1 | [root@iZbp16w4b9baac6xlzfcdmZ home]# ls |
删除f1后,查看 f2 和 f3 的区别:
1 | [root@iZbp16w4b9baac6xlzfcdmZ home]# rm -rf f1 |
注意:只要源文件发生改变,链接文件也会发生改变
硬连接
硬连接指通过索引节点来进行连接。在 Linux 的文件系统中,保存在磁盘分区中的文件不管是什么类型都给它分配一个编号,称为索引节点号(Inode Index)。在 Linux 中,多个文件名指向同一索引节点是存在的。比如:A 是 B 的硬链接(A 和 B 都是文件名),则 A 的目录项中的 inode 节点号与 B 的目录项中的 inode 节点号相同,即一个 inode 节点对应两个不同的文件名,两个文件名指向同一个文件,A 和 B 对文件系统来说是完全平等的。删除其中任何一个都不会影响另外一个的访问。
硬连接的作用是允许一个文件拥有多个有效路径名,这样用户就可以建立硬连接到重要文件,以防止“误删”的功能。其原因如上所述,因为对应该目录的索引节点有一个以上的连接。只删除一个连接并不影响索引节点本身和其它的连接,只有当最后一个连接被删除后,文件的数据块及目录的连接才会被释放。也就是说,文件真正删除的条件是与之相关的所有硬连接文件均被删除。
软连接
另外一种连接称之为符号连接(Symbolic Link),也叫软连接。软链接文件有类似于 Windows 的快捷方式。它实际上是一个特殊的文件。在符号连接中,文件实际上是一个文本文件,其中包含的有另一文件的位置信息。比如:A 是 B 的软链接(A 和 B 都是文件名),A 的目录项中的 inode 节点号与 B 的目录项中的 inode 节点号不相同,A 和 B 指向的是两个不同的 inode,继而指向两块不同的数据块。但是 A 的数据块中存放的只是 B 的路径名(可以根据这个找到 B 的目录项)。A 和 B 之间是“主从”关系,如果 B 被删除了,A 仍然存在(因为两个是不同的文件),但指向的是一个无效的链接。
测试:
1 | [root@qeuroal /]# cd /home |
从上面的结果中可以看出,硬连接文件 f2 与原文件 f1 的 inode 节点相同,均为 397247,然而符号连接文件的 inode 节点不同。
1 | # echo 字符串输出 >> f1 输出到 f1文件 |
通过上面的测试可以看出:当删除原始文件 f1 后,硬连接 f2 不受影响,但是符号连接 f1 文件无效;
依此您可以做一些相关的测试,可以得到以下全部结论:
- 删除符号连接
f3,对f1,f2无影响; - 删除硬连接
f2,对f1,f3也无影响; - 删除原文件
f1,对硬连接f2没有影响,导致符号连接f3失效; - 同时删除原文件
f1,硬连接f2,整个文件会真正的被删除。
Vim编辑器
简介
Vim是从 vi 发展出来的一个文本编辑器。代码补完、编译及错误跳转等方便编程的功能特别丰富,在程序员中被广泛使用。尤其是Linux中,必须要会使用vim:查看内容、编辑内容、保存内容。
简单的来说, vi 是老式的字处理器,不过功能已经很齐全了,但是还是有可以进步的地方。
vim 则可以说是程序开发者的一项很好用的工具。
所有的 Unix Like 系统都会内建 vi 文书编辑器,其他的文书编辑器则不一定会存在。
连 vim 的官方网站 (http://www.vim.org) 自己也说 vim 是一个程序开发工具而不是文字处理软件。
补充:
vim可以看成vi的升级版;vim通过一些插件可以实现和IDE一样的功能;
Vim键盘图

三种使用模式
基本上 vi/vim 共分为三种模式,分别是命令模式(Command mode),输入模式(Insert mode)和底线命令模式(Last line mode)。这三种模式的作用分别是:
命令模式:
用户刚刚启动 vi/vim,便进入了命令模式。

此状态下敲击键盘动作会被Vim识别为命令,而非输入字符。比如我们此时按下i,并不会输入一个字符,i被当作了一个命令。
以下是常用的几个命令:
| 命令 | 说明 | 备注 |
|---|---|---|
| i | 切换到输入模式,以输入字符。 |  |
| x | 删除当前光标所在处的字符。 | |
| : | 切换到底线命令模式,以在最底一行输入命令。 | 如果是编辑模式,需要先退出编辑模式:ESC |
若想要编辑文本:启动Vim,进入了命令模式,按下i,切换到输入模式。
命令模式只有一些最基本的命令,因此仍要依靠底线命令模式输入更多命令。
输入模式:
在命令模式下按下i就进入了输入模式。
在输入模式中,可以使用以下按键:
| 命令 | 说明 | 备注 |
|---|---|---|
| 字符按键以及Shift组合 | 输入字符 | |
| ENTER | 回车键,换行 | |
| BACK SPACE | 退格键,删除光标前一个字符 | |
| DEL | 删除键,删除光标后一个字符 | |
| 方向键 | 在文本中移动光标 | |
| HOME/END | 移动光标到行首/行尾 | |
| Page Up/Page Down | 上/下翻页 | |
| Insert | 切换光标为输入/替换模式,光标将变成竖线/下划线 | |
| ESC | 退出输入模式,切换到命令模式 |
底线命令模式
在命令模式下按下:(英文冒号)就进入了底线命令模式。光标就移动到了最下面,就可以在这里输入一些底线命令了!

底线命令模式可以输入单个或多个字符的命令,可用的命令非常多。
在底线命令模式中,基本的命令有(已经省略了冒号):
q退出程序w保存文件

按ESC键可随时退出底线命令模式。

简单的说,我们可以将这三个模式想成底下的图标来表示:

体验
如果你想要使用 vi 来建立一个名为 test.txt 的文件时,你可以这样做:
1 | [root@qeuroal home]# vim test.txt |
然后就会进入文件
按下 i 进入输入模式(也称为编辑模式),开始编辑文字
在一般模式之中,只要按下 i, o, a 等字符就可以进入输入模式了!
在编辑模式当中,你可以发现在左下角状态栏中会出现 –INSERT- 的字样,那就是可以输入任意字符的提示。
这个时候,键盘上除了 Esc 这个按键之外,其他的按键都可以视作为一般的输入按钮了,所以你可以进行任何的编辑。
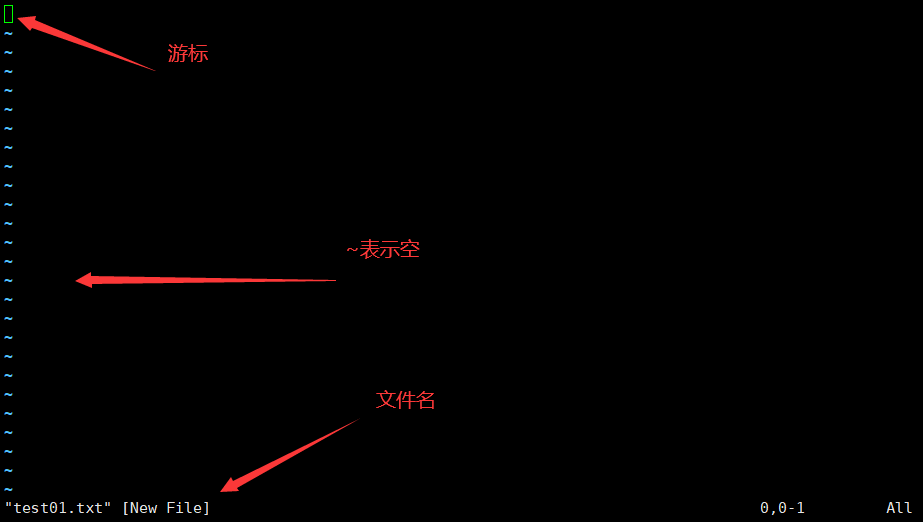
按下 ESC 按钮回到一般模式
好了,假设我已经按照上面的样式给他编辑完毕了,那么应该要如何退出呢?是的!没错!就是给他按下 Esc 这个按钮即可!马上你就会发现画面左下角的 – INSERT – 不见了!
在一般模式中按下 :wq 储存后离开 vim!
OK! 这样我们就成功创建了一个 test.txt 的文件。
Vim按键说明
除了上面简易范例的 i, Esc, :wq 之外,其实 vim 还有非常多的按键可以使用。
第一部分:一般模式可用的光标移动、复制粘贴、搜索替换等
| 移动光标的方法 | 说明 | 备注 |
|---|---|---|
h 或 向左箭头键(←) |
光标向左移动一个字符 | |
j 或 向下箭头键(↓) |
光标向下移动一个字符 | |
k 或 向上箭头键(↑) |
光标向上移动一个字符 | |
l 或 向右箭头键(→) |
光标向右移动一个字符 | |
[Ctrl] + [f] |
屏幕『向下』移动一页,相当于 [Page Down]按键 (常用) | |
[Ctrl] + [b] |
屏幕『向上』移动一页,相当于 [Page Up] 按键 (常用) | |
[Ctrl] + [d] |
屏幕『向下』移动半页 | |
[Ctrl] + [u] |
屏幕『向上』移动半页 | |
+ |
光标移动到非空格符的下一行 | |
- |
光标移动到非空格符的上一行 | 配置文件中,空格较多 |
n< space> |
那个 n 表示『数字』,例如 20 。按下数字后再按空格键,光标会向右移动这一行的 n 个字符。 | 快捷切换光标 |
0 或功能键[Home] |
这是数字『 0 』:移动到这一行的最前面字符处 (常用) | |
$ 或功能键[End] |
移动到这一行的最后面字符处(常用) | |
H |
光标移动到这个屏幕的最上方那一行的第一个字符 | |
M |
光标移动到这个屏幕的中央那一行的第一个字符 | |
L |
光标移动到这个屏幕的最下方那一行的第一个字符 | |
G |
移动到这个档案的最后一行(常用) | |
nG |
n 为数字。移动到这个档案的第 n 行。例如 20G 则会移动到这个档案的第 20 行(可配合 :set nu) | |
gg |
移动到这个档案的第一行,相当于 1G 啊!(常用) | |
n< Enter> |
n 为数字。光标向下移动 n 行(常用) |
| 搜索替换 | |
|---|---|
/word |
向光标之下寻找一个名称为 word 的字符串。例如要在档案内搜寻 vbird 这个字符串,就输入 /vbird 即可!(常用) |
?word |
向光标之上寻找一个字符串名称为 word 的字符串。 |
n |
这个 n 是英文按键。代表重复前一个搜寻的动作。举例来说, 如果刚刚我们执行 /vbird 去向下搜寻 vbird 这个字符串,则按下 n 后,会向下继续搜寻下一个名称为 vbird 的字符串。如果是执行 ?vbird 的话,那么按下 n 则会向上继续搜寻名称为 vbird 的字符串! |
N |
这个 N 是英文按键。与 n 刚好相反,为『反向』进行前一个搜寻动作。例如 /vbird 后,按下 N 则表示『向上』搜寻 vbird 。 |
| 删除、复制与粘贴 | 说明 |
|---|---|
x, X |
在一行字当中,x 为向后删除一个字符 (相当于 [del] 按键), X 为向前删除一个字符(相当于 [backspace] 亦即是退格键) (常用) |
nx |
n 为数字,连续向后删除 n 个字符。举例来说,我要连续删除 10 个字符, 『10x』。 |
dd |
删除游标所在的那一整行(常用) |
ndd |
n 为数字。删除光标所在的向下 n 行,例如 20dd 则是删除 20 行 (常用) |
d1G |
删除光标所在到第一行的所有数据 |
dG |
删除光标所在到最后一行的所有数据 |
d$ |
删除游标所在处,到该行的最后一个字符 |
d0 |
那个是数字的 0 ,删除游标所在处,到该行的最前面一个字符 |
yy |
复制游标所在的那一行(常用) |
nyy |
n 为数字。复制光标所在的向下 n 行,例如 20yy 则是复制 20 行(常用) |
y1G |
复制游标所在行到第一行的所有数据 |
yG |
复制游标所在行到最后一行的所有数据 |
y0 |
复制光标所在的那个字符到该行行首的所有数据 |
y$ |
复制光标所在的那个字符到该行行尾的所有数据 |
p, P |
p 为将已复制的数据在光标下一行贴上,P 则为贴在游标上一行!举例来说,我目前光标在第 20 行,且已经复制了 10 行数据。则按下 p 后, 那 10 行数据会贴在原本的 20 行之后,亦即由 21 行开始贴。但如果是按下 P 呢?那么原本的第 20 行会被推到变成 30 行。(常用) |
J |
将光标所在行与下一行的数据结合成同一行 |
c |
重复删除多个数据,例如向下删除 10 行,[ 10cj ] |
u |
复原前一个动作。(常用) |
[Ctrl]+r |
重做上一个动作。(常用) |
第二部分:一般模式切换到编辑模式的可用的按钮说明
| 进入输入或取代的编辑模式 | 说明 |
|---|---|
i, I |
进入输入模式(Insert mode):i 为『从目前光标所在处输入』, I 为『在目前所在行的第一个非空格符处开始输入』。(常用) |
a, A |
进入输入模式(Insert mode):a 为『从目前光标所在的下一个字符处开始输入』, A 为『从光标所在行的最后一个字符处开始输入』。(常用) |
o, O |
进入输入模式(Insert mode):这是英文字母 o 的大小写。o 为『在目前光标所在的下一行处输入新的一行』;O 为在目前光标所在处的上一行输入新的一行!(常用) |
r, R |
进入取代模式(Replace mode):r 只会取代光标所在的那一个字符一次;R会一直取代光标所在的文字,直到按下 ESC 为止;(常用) |
[Esc] |
退出编辑模式,回到一般模式中(常用) |
第三部分:一般模式切换到指令行模式的可用的按钮说明
| 指令行的储存、离开等指令 | 说明 | 备注 |
|---|---|---|
:w |
将编辑的数据写入硬盘档案中(常用) | |
:w! |
若文件属性为『只读』时,强制写入该档案。不过,到底能不能写入, 还是跟你对该档案的档案权限有关啊! | |
:q |
离开 vi (常用) |
|
:q! |
若曾修改过档案,又不想储存,使用 ! 为强制离开不储存档案。 |
注意一下啊,那个惊叹号 (!) 在 vi 当中,常常具有『强制』的意思~ |
:wq |
储存后离开,若为 :wq! 则为强制储存后离开 (常用) |
|
ZZ |
这是大写的 Z 喔!若档案没有更动,则不储存离开,若档案已经被更动过,则储存后离开! |
|
:w [filename] |
将编辑的数据储存成另一个档案(类似另存新档) | |
:r [filename] |
在编辑的数据中,读入另一个档案的数据。亦即将 『filename』 这个档案内容加到游标所在行后面 |
|
:n1,n2 w [filename] |
将 n1 到 n2 的内容储存成 filename 这个档案。 |
|
:! command |
暂时离开 vi 到指令行模式下执行 command 的显示结果!例如 『:! ls /home』即可在 vi 当中看 /home 底下以 ls 输出的档案信息! |
|
:set nu |
显示行号,设定之后,会在每一行的前缀显示该行的行号 | 设置行号,代码中经常会使用 |
:set nonu |
与 set nu 相反,为取消行号! |
账号管理
一般在公司中国,用的应该都不是root账户!
简介
Linux系统是一个多用户多任务的分时操作系统,任何一个要使用系统资源的用户,都必须首先向系统管理员申请一个账号,然后以这个账号的身份进入系统。
用户的账号一方面可以帮助系统管理员对使用系统的用户进行跟踪,并控制他们对系统资源的访问;另一方面也可以帮助用户组织文件,并为用户提供安全性保护。
每个用户账号都拥有一个唯一的用户名和各自的口令。
用户在登录时键入正确的用户名和口令后,就能够进入系统和自己的主目录。
实现用户账号的管理,要完成的工作主要有如下几个方面:
- 用户账号的添加、删除与修改。
- 用户口令的管理。
- 用户组的管理。
用户账号的管理
用户账号的管理工作主要涉及到用户账号的添加、修改和删除。
添加用户账号就是在系统中创建一个新账号,然后为新账号分配用户号、用户组、主目录和登录Shell等资源。
属主,属组
添加账号
useradd
1 | useradd 选项 用户名 |
参数说明:
- 选项 :
- -c comment 指定一段注释性描述。
- -d 目录 指定用户主目录,如果此目录不存在,则同时使用-m选项,可以创建主目录。
- -g 用户组 指定用户所属的用户组。
- -G 用户组,用户组 指定用户所属的附加组。
- -m 使用者目录如不存在则自动建立。自动创建这个用户的主目录
/home/qeuroal/ - -s Shell文件 指定用户的登录Shell。
- -u 用户号 指定用户的用户号,如果同时有-o选项,则可以重复使用其他用户的标识号。
- 用户名 :
- 指定新账号的登录名。
测试:
1 | # 此命令创建了一个用户qeuroal,其中-m选项用来为登录名qeuroal产生一个主目录 /home/qeuroal |
增加用户账号就是在/etc/passwd文件中为新用户增加一条记录,同时更新其他系统文件如/etc/shadow, /etc/group等。
理解本质:
Linux中一切皆文件,这里的添加用户说白了就是往某一个文件中写入用户的信息了!/etc/passwd
adduser 命令添加新用户
在Ubuntu中,有两个命令可用于创建新的用户。分别是useradd和adduser。useradd是一个用于添加用户的最普遍命令,所有发行版都支持。
而adduser是useradd的友好交互式前端,adduser是用Perl语言编写的。我们建议如果你在编写shell脚本时使用useradd添加用户。
如果你只是手动创建一个或者几个用户,在ubuntu中建议你使用adduser,adduser可以在一条命令完成创建用户的过程。
如果你需要在批量创建用户请参考我们的教程,Linux useradd命令创建用户。
要在Ubuntu创建用户,请运行命令adduser,后跟用户名作为参数。例如命令sudo adduser myfreax将会创建用户myfreax。
命令将向你询问一系列的问题。密码是必需的,其他字段都是可选的。
1 | sudo adduser myfreax |
区别
使用 sudo useradd newuser 后 /home 里并没有 newuser 的目录。
查询得知,可以用 useradd -m newuser,但是-m这个命令只有在你创建用户的时候才有用。
如果已经创建了用户且没有目录的话,useradd -m newuser是不会为用户创建目录的,也就是说必须删掉这个用户再重新useradd -m newuser才可以。
但是!使用adduser的话直接adduser username也会有目录,不用像useradd那样用-m了。但是 adduser一创建就会要求输入密码。useradd创建的时候就不会要求输入密码。
超级用户
默认情况下,在Ubuntu,sudo组的成员被授予sudo访问权限。如果您希望新创建的用户具有sudo权限,请将用户添加到sudo组。
修改用户所属组的命令是usermod命令,我们不建议直接修改用户主要组。这可能导致某些权限问题。最好的方式将用户追加到sudo组中。
因此你将使用usermod命令的-aG选项,添加用户到sudo组,-a表示追加用户到指定组,-G选项表示不要将用户从其它组中移除。
1 | sudo usermod -aG sudo username |
删除帐号
userdel命令删除用户
如果一个用户的账号不再使用,可以从系统中删除。
删除用户账号就是要将/etc/passwd等系统文件中的该用户记录删除,必要时还删除用户的主目录。
删除一个已有的用户账号使用userdel命令,其格式如下:
1 | userdel 选项 用户名 |
常用的选项是 -r,它的作用是把用户的主目录一起删除。
1 | [root@iZbp16w4b9baac6xlzfcdmZ ~]# useradd -m qeuroal |
此命令删除用户qeuroal在系统文件中(主要是/etc/passwd, /etc/shadow, /etc/group等)的记录,同时删除用户的主目录。
deluser 命令删除用户
如果不再需要用户,可以从命令行或通过GUI删除它。在ubuntu中删除用户方式也是有两种。
您可以使用两个命令来删除用户,分别是userdel和deluser。在Ubuntu,建议您使用deluser命令,因为它比userdel更友好。
同样在脚本中,我们建议你使用userdel而不是deluser。因为其它发行版不存在deluser。deluser仅在基于Ubuntu的发行版存在。
deluser仅在指定用户参数时,deluser将删除用户而不删除用户文件。如果你需要用户的家目录和邮件等信息请使用--remove-home选项。
1 | sudo deluser username |
步骤
删除用户的操作分为 3 步:
- 执行
userdel:sudo userdel dongyuanxin_2016150127 - 删除用户目录:
sudo rm -rf /home/dongyuanxin_2016150127 - 删除用户权限相关配置:删除或者注释掉
/etc/sudoers中关于要删除用户的配置,否则无法再次创建同名用户。
修改帐号
修改用户账号就是根据实际情况更改用户的有关属性,如用户号、主目录、用户组、登录Shell等。
修改已有用户的信息使用usermod命令,其格式如下:
1 | usermod 选项 用户名 |
常用的选项包括-c, -d, -m, -g, -G, -s, -u以及-o等,这些选项的意义与useradd命令中的选项一样,可以为用户指定新的资源值。
例如:
1 | # usermod -s /bin/ksh -d /home/z –g developer qeuroal |
修改完毕后查看配置文件即可:
1 | cat /etc/passwd |
此命令将用户qeuroal的登录Shell修改为ksh,主目录改为/home/z,用户组改为developer。
Linux下如何切换用户
root 用户

切换用户的命令为:
su username【username是你的用户名哦】
从普通用户切换到root用户,还可以使用命令:
sudo su在终端输入
exit或logout或使用快捷方式ctrl+d,可以退回到原来用户,其实ctrl+d也是执行的exit命令
在切换用户时,如果想在切换用户之后使用新用户的工作环境,可以在
su和username之间加-,例如:【su - root】


| 符号 | 说明 | 备注 |
|---|---|---|
$ |
表示普通用户 | |
# |
表示超级用户,也就是root用户 |
补充
在阿里云买的服务器是一段随机字符串,可以通过以下方式修改:

用户口令的管理
用户管理的一项重要内容是用户口令的管理。用户账号刚创建时没有口令,但是被系统锁定,无法使用,必须为其指定口令后才可以使用,即使是指定空口令。
指定和修改用户口令的Shell命令是passwd。超级用户(root)可以为自己和其他用户指定口令,普通用户只能用它修改自己的口令。
linux上输入密码不会显示,正常输入即可,并不是系统的问题!
在公司中,一般拿不到公司服务器的root权限,都是一些分配的账号!
超级用户:
命令的格式为:
1 | passwd 选项 用户名 |
可使用的选项:
-l锁定口令,即禁用账号。-u口令解锁。-d使账号无口令。-强迫用户下次登录时修改口令。
普通用户名:
修改当前用户的口令。
例如,假设当前用户是qeuroal,则下面的命令修改该用户自己的口令:
1 | $ passwd |
如果是超级用户,可以用下列形式指定任何用户的口令:
1 | # passwd qeuroal |
普通用户修改自己的口令时,passwd命令会先询问原口令,验证后再要求用户输入两遍新口令,如果两次输入的口令一致,则将这个口令指定给用户;而超级用户为用户指定口令时,就不需要知道原口令。
为了系统安全起见,用户应该选择比较复杂的口令,例如最好使用8位长的口令,口令中包含有大写、小写字母和数字,并且应该与姓名、生日等不相同。
锁定账户
例如:test_user辞职了,冻结这个账号,一旦冻结,这个人就登录不上系统了。
为用户指定空口令时,执行下列形式的命令:
1 | passwd -d test_user # 没有密码不能登录 |
此命令将用户 test_user的口令删除,这样用户 test_user下一次登录时,系统就不再允许该用户登录了。
passwd 命令还可以用 -l(lock) 选项锁定某一用户,使其不能登录,例如:
1 | passwd -l test_user # 锁定之后这个用户就不能登录了 |

在公司中一般触及不到 root 用户!作为一个开发一般拿不到!如果拿到root账号后,首先把自己的权限提到最高,自己用户的组提到root组。
用户组管理
属主、属组
每个用户都有一个用户组,系统可以对一个用户组中的所有用户进行集中管理(开发、测试、运维、root)。不同Linux 系统对用户组的规定有所不同,如Linux下的用户属于与它同名的用户组,这个用户组在创建用户时同时创建。
用户组的管理涉及用户组的添加、删除和修改。组的增加、删除和修改实际上就是对/etc/group文件的更新。
增加用户组
增加一个新的用户组使用groupadd命令
1 | groupadd 选项 用户组 |
可以使用的选项有:
-g GID指定新用户组的组标识号(GID)。-o一般与-g选项同时使用,表示新用户组的GID可以与系统已有用户组的GID相同。
实例1:
1 | # groupadd group1 |
此命令向系统中增加了一个新组group1,新组的组标识号是在当前已有的最大组标识号的基础上加1。
创建完一个用户组后可以得到一个组的 id,这个 id 是可以指定的!
实例2:
1 | # groupadd -g 101 group2 |
此命令向系统中增加了一个新组group2,同时指定新组的组标识号是101。
如果不指定就是自增 1
删除用户组
如果要删除一个已有的用户组,使用groupdel命令
1 | groupdel 用户组 |
例如:
1 | # groupdel group1 |
此命令从系统中删除组group1。
修改用户组的属性
使用groupmod命令
1 | groupmod 选项 用户组 |
常用的选项有:
-g GID为用户组指定新的组标识号。-o与-g选项同时使用,用户组的新GID可以与系统已有用户组的GID相同。-n新用户组 将用户组的名字改为新名字
1 | # 此命令将组group2的组标识号修改为102。 |
拓展:文件的查看
/etc/passwd
完成用户管理的工作有许多种方法,但是每一种方法实际上都是对有关的系统文件进行修改。
与用户和用户组相关的信息都存放在一些系统文件中,这些文件包括/etc/passwd, /etc/shadow, /etc/group等。
下面分别介绍这些文件的内容。
/etc/passwd文件是用户管理工作涉及的最重要的一个文件。
Linux系统中的每个用户都在/etc/passwd文件中有一个对应的记录行,它记录了这个用户的一些基本属性(主目录、属组)。
这个文件对所有用户都是可读的。它的内容类似下面的例子:
1 | # cat /etc/passwd |
从上面的例子我们可以看到,/etc/passwd中一行记录对应着一个用户,每行记录又被冒号(:)分隔为7个字段,其格式和具体含义如下:
1 | 用户名:口令(登录密码,我们不可见):用户标识号:组标识号:注释性描述:主目录:登录Shell |
“用户名”是代表用户账号的字符串。
通常长度不超过8个字符,并且由大小写字母和/或数字组成。登录名中不能有冒号(:),因为冒号在这里是分隔符。
为了兼容起见,登录名中最好不要包含点字符(.),并且不使用连字符(-)和加号(+)打头。
“口令”一些系统中,存放着加密后的用户口令字。
虽然这个字段存放的只是用户口令的加密串,不是明文,但是由于
/etc/passwd文件对所有用户都可读,所以这仍是一个安全隐患。因此,现在许多Linux系统(如SVR4)都使用了shadow技术,把真正的加密后的用户口令字存放到/etc/shadow文件中,而在/etc/passwd文件的口令字段中只存放一个特殊的字符,例如“x”或者“*”。“用户标识号”是一个整数,系统内部用它来标识用户。
一般情况下它与用户名是一一对应的。如果几个用户名对应的用户标识号是一样的,系统内部将把它们视为同一个用户,但是它们可以有不同的口令、不同的主目录以及不同的登录
Shell等。通常用户标识号的取值范围是
0~65 535。0是超级用户root的标识号,1~99由系统保留,作为管理账号,普通用户的标识号从100开始。在Linux系统中,这个界限是500。“组标识号”字段记录的是用户所属的用户组。
它对应着
/etc/group文件中的一条记录。“注释性描述”字段记录着用户的一些个人情况。
例如用户的真实姓名、电话、地址等,这个字段并没有什么实际的用途。在不同的
Linux系统中,这个字段的格式并没有统一。在许多Linux系统中,这个字段存放的是一段任意的注释性描述文字,用作finger命令的输出。“主目录”,也就是用户的起始工作目录。
它是用户在登录到系统之后所处的目录。在大多数系统中,各用户的主目录都被组织在同一个特定的目录下,而用户主目录的名称就是该用户的登录名。各用户对自己的主目录有读、写、执行(搜索)权限,其他用户对此目录的访问权限则根据具体情况设置。
用户登录后,要启动一个进程,负责将用户的操作传给内核,这个进程是用户登录到系统后运行的命令解释器或某个特定的程序,即Shell。
Shell是用户与Linux系统之间的接口。Linux的Shell有许多种,每种都有不同的特点。常用的有sh(Bourne Shell), csh(C Shell), ksh(Korn Shell), tcsh(TENEX/TOPS-20 type C Shell), bash(Bourne Again Shell)等。系统管理员可以根据系统情况和用户习惯为用户指定某个
Shell。如果不指定Shell,那么系统使用sh为默认的登录Shell,即这个字段的值为/bin/sh。用户的登录
Shell也可以指定为某个特定的程序(此程序不是一个命令解释器)。利用这一特点,我们可以限制用户只能运行指定的应用程序,在该应用程序运行结束后,用户就自动退出了系统。有些
Linux系统要求只有那些在系统中登记了的程序才能出现在这个字段中。系统中有一类用户称为伪用户(
pseudo users)这些用户在
/etc/passwd文件中也占有一条记录,但是不能登录,因为它们的登录Shell为空。它们的存在主要是方便系统管理,满足相应的系统进程对文件属主的要求。常见的伪用户如下所示:
伪用户 含 义 bin 拥有可执行的用户命令文件 sys 拥有系统文件 adm 拥有帐户文件 uucp UUCP使用 lp lp或lpd子系统使用 nobody NFS使用
/etc/shadow
1、除了上面列出的伪用户外,还有许多标准的伪用户,例如:audit, cron, mail, usenet等,它们也都各自为相关的进程和文件所需要。
由于/etc/passwd文件是所有用户都可读的,如果用户的密码太简单或规律比较明显的话,一台普通的计算机就能够很容易地将它破解,因此对安全性要求较高的Linux系统都把加密后的口令字分离出来,单独存放在一个文件中,这个文件是/etc/shadow文件。有超级用户才拥有该文件读权限,这就保证了用户密码的安全性。
**2、/etc/shadow中的记录行与/etc/passwd**中的一一对应,它由pwconv命令根据/etc/passwd中的数据自动产生
它的文件格式与/etc/passwd类似,由若干个字段组成,字段之间用”:”隔开。这些字段是:
1 | 登录名:加密口令:最后一次修改时间:最小时间间隔:最大时间间隔:警告时间:不活动时间:失效时间:标志 |
- “登录名”是与
/etc/passwd文件中的登录名相一致的用户账号 - “口令”字段存放的是加密后的用户口令字,长度为13个字符。如果为空,则对应用户没有口令,登录时不需要口令;如果含有不属于集合
{ ./0-9A-Za-z }中的字符,则对应的用户不能登录。 - “最后一次修改时间”表示的是从某个时刻起,到用户最后一次修改口令时的天数。时间起点对不同的系统可能不一样。例如在
SCO Linux中,这个时间起点是1970年1月1日。 - “最小时间间隔”指的是两次修改口令之间所需的最小天数。
- “最大时间间隔”指的是口令保持有效的最大天数。
- “警告时间”字段表示的是从系统开始警告用户到用户密码正式失效之间的天数。
- “不活动时间”表示的是用户没有登录活动但账号仍能保持有效的最大天数。
- “失效时间”字段给出的是一个绝对的天数,如果使用了这个字段,那么就给出相应账号的生存期。期满后,该账号就不再是一个合法的账号,也就不能再用来登录了。
/etc/group
用户组的所有信息都存放在/etc/group文件中。
将用户分组是Linux 系统中对用户进行管理及控制访问权限的一种手段。
每个用户都属于某个用户组;一个组中可以有多个用户,一个用户也可以属于不同的组。
当一个用户同时是多个组中的成员时,在/etc/passwd文件中记录的是用户所属的主组,也就是登录时所属的默认组,而其他组称为附加组。
用户要访问属于附加组的文件时,必须首先使用newgrp命令使自己成为所要访问的组中的成员。
用户组的所有信息都存放在/etc/group文件中。此文件的格式也类似于/etc/passwd文件,由冒号(:)隔开若干个字段,这些字段有:
1 | 组名:口令:组标识号:组内用户列表 |
- “组名”是用户组的名称,由字母或数字构成。与
/etc/passwd中的登录名一样,组名不应重复。 - “口令”字段存放的是用户组加密后的口令字。一般
Linux系统的用户组都没有口令,即这个字段一般为空,或者是*。(当然,你看不到明文密码) - “组标识号”与用户标识号类似,也是一个整数,被系统内部用来标识组。即: 组的ID, GID
- “组内用户列表”是属于这个组的所有用户的列表/b],不同用户之间用逗号(
,)分隔。这个用户组可能是用户的主组,也可能是附加组。
1 | adm:x:4:syslog,admin |
以下为各字段的说明:
- adm 为组名称;
- x 代表密码字段(当然你不会看到明文的密码);
- 4 是组的ID即GID;
- syslog 和 admin 是属于组 adm 中的用户。
切换组
如果一个用户同时属于多个用户组,那么用户可以在用户组之间切换,以便具有其他用户组的权限。
用户可以在登录后,使用命令newgrp切换到其他用户组,这个命令的参数就是目的用户组。例如:
1 | $ newgrp root |
这条命令将当前用户切换到root用户组,前提条件是root用户组确实是该用户的主组或附加组。
磁盘管理
概述
Linux磁盘管理好坏直接关系到整个系统的性能问题。
Linux磁盘管理常用命令为 df、du。
df:列出文件系统的整体磁盘使用量du:检查磁盘空间使用量
df
df:列出文件系统整体的磁盘使用量
df命令参数功能:检查文件系统的磁盘空间占用情况。可以利用该命令来获取硬盘被占用了多少空间,目前还剩下多少空间等信息。
语法:
1 | df [-ahikHTm] [目录或文件名] |
选项与参数:
- -a :列出所有的文件系统,包括系统特有的
/proc等文件系统; - -k :以
KBytes的容量显示各文件系统; - -m :以
MBytes的容量显示各文件系统; - -h :以人们较易阅读的
GBytes,MBytes,KBytes等格式自行显示; - -H :以
M=1000K取代M=1024K的进位方式; - -T :显示文件系统类型, 连同该
partition的filesystem名称 (例如ext3) 也列出; - -i :不用硬盘容量,而以
inode的数量来显示
测试:
1 | # 将系统内所有的文件系统列出来! |
du
du:检查当前磁盘空间使用量
Linux du命令也是查看使用空间的,但是与df命令不同的是Linux du命令是对文件和目录磁盘使用的空间的查看,还是和df命令有一些区别的,这里介绍Linux du命令。
语法:
1 | du [-ahskm] 文件或目录名称 |
选项与参数:
-a:列出所有的文件与目录容量,可以看到子文件夹,因为默认仅统计目录底下的文件量而已。-h:以人们较易读的容量格式 (G/M) 显示;-s:列出总量而已,而不列出每个各别的目录占用容量;-S:不包括子目录下的总计,与-s有点差别。-k:以KBytes列出容量显示;-m:以MBytes列出容量显示;
测试:
1 | # 只列出当前目录下的所有文件夹容量(包括隐藏文件夹): |
通配符 * 来代表每个目录。
与 df 不一样的是,du 这个命令其实会直接到文件系统内去搜寻所有的文件数据。

磁盘挂载与卸除
起因:Mac或 Linux 挂载本地磁盘或者文件
根文件系统之外的其他文件要想能够被访问,都必须通过“关联”至根文件系统上的某个目录来实现,此关联操作即为“挂载”,此目录即为“挂载点”,解除此关联关系的过程称之为“卸载”
Linux 的磁盘挂载使用mount命令,卸载使用umount命令。
磁盘挂载语法:
1 | mount [-t 文件系统] [-L Label名] [-o 额外选项] [-n] 装置文件名 挂载点 |
测试:
1 | # 将 /dev/hdc6 挂载到 /mnt/hdc6 上面! |

磁盘卸载命令 umount 语法:
1 | umount [-fn] 装置文件名或挂载点 |
选项与参数:
-f:强制卸除!可用在类似网络文件系统 (NFS) 无法读取到的情况下;-n:不升级/etc/mtab情况下卸除。
卸载/dev/hdc6
1 | [root@www ~]# umount /dev/hdc6 |
除了这个之外,以后安装了JDK ,可以使用 java 中的一些命令来查看信息。
进程管理
Linux中一切皆文件(Linux:系统:(磁盘、进程)。文件:读写执行(查看,创建,删除,移动,复制,编辑),权限(用户、用户组)。)
对于我们开发人员来说,其实 Linux 更多偏向于使用即可!
进程基本概念
- 在
Linux中,每一个程序都有自己的一个进程,每一个进程都有一个id号; - 每个进程都有一个父进程(被谁创建的);
- 进程可以有两种存在方式:前台!后台运行!
- 一般的话服务都是后台运行的,基本的程序都是前台运行的;
命令
查看进程
ps : 查看当前系统中正在执行的各种进程的信息
ps -xxx : 通过 ps -help 或 man ps 查看帮助文档
-a: 显示当前终端运行的所有的进程信息(当期的进程,1个);-u: 以用户的信息显示进程();-x: 显示后台运行进程的参数;
实例
ps -aux | grep mysql
补充
|: 在Linux中,这个叫做管道符,如:A|B: 把A命令的结果作为输出操作B命令grep: 查找文件中符合条件的字符串对于我们来说,这里目前只需要记住一个命令即可:
ps -xxx | grep 进程名过滤进程信息ps -ef: 可以查到父进程信息1
ps -ef | grep mysql # 看父进程我们一般可以通过目录树结构查看
pstree: 进程树-p: 显示父id-u: 显示用户组实践
1
pstree -pu


结束进程
杀死进程,等价于 window 结束任务
1 | kill -9 进程id # 表示强制结束该进程 |
在服务器很少手动结束进程,平时写的代码死循环了,可以选择结束进程!杀进程!
shell
getopts
getpots是Shell命令行参数解析工具,旨在从Shell Script的命令行当中解析参数。
getopt
SSH
上传
上传本地文件到服务器
格式:scp 要上传的文件路径 用户名@服务器地址:服务器保存路径
例如:把本机 /home/test.txt 文件上传到 192.168.0.101 这台服务器上的 /data/ 目录中
1 | scp /home/test.txt root@192.168.0.101:/data/ |
上传目录到服务器
格式:scp -r 要上传的目录 用户名@服务器地址:服务器的保存目录
例如:把 /home 目录上传到服务器的 /data/ 目录
1 | scp -r /home root@192.168.0.101:/data/ |
下载
从服务器上下载文件
格式:scp 用户名@服务器地址:要下载的文件路径 保存文件的文件夹路径
例如:把 192.168.0.101 上的 /data/test.txt 的文件下载到 /home(本地目录)
1 | scp root@192.168.0.101:/data/test.txt /home |
从服务器下载整个目录
格式:scp -r 用户名@服务器地址:要下载的服务器目录 保存下载的目录
例如:把 192.168.0.101 上的 /data 目录下载到 /home(本地目录)
1 | scp -r root@192.168.0.101:/data /home/ |
注:目标服务器要开启写入权限。
命令
总览
基础命令相关一:
1
2cd、ls、pwd、help、man、if、for、while、case、select、read、test、ansible、iptables、
firewall-cmd、salt、mv、cut、uniq、sort、wc、source、sestatus、setenforce;基础命令相关二:
1
2date、ntpdate、crontab、rsync、ssh、scp、nohup、sh、bash、hostname、hostnamectl、
source、ulimit、export、env、set、at、dir、db_load、diff、dmsetup、declare;用户权限相关:
1
2
3Useradd、userdel、usermod、groupadd、groupmod、groupdel、Chmod、chown、
chgrp、umask、chattr、lsattr、id、who、whoami、last、su、sudo、w、chpasswd、
chroot;文件管理相关:
1
2Touch、mkdir、rm、rmdi、vi、vim、cat、head、tail、less、more、find、sed、
grep、awk、echo、ln、stat、file;软件资源管理:
1
2Rpm、yum、tar、unzip、zip、gzip、wget、curl、rz、sz、jar、apt-get、bzip2、
service、systemctl、make、cmake、chkconfig;系统资源管理:
1
2fdisk、mount、umount、mkfs.ext4、fsck.ext4、parted、lvm、dd、du、df、top、
iftop、free、w、uptime、iostat、vmstat、iotop、ps、netstat、lsof、ss、sar;网络管理相关:
1
2ping、ifconfig、ip addr、ifup、ifdown、nmcli、route、nslookup、traceroute、
dig、tcpdump、nmap、brctl、ethtool、setup、arp、ab、iperf;
grep
基本格式
1 | grep [option] pattern file |
常用参数
| 参数 | 含义 |
|---|---|
| -b | 显示匹配行距文件头部的偏移量 |
| -c | 只显示匹配的行数 |
| -e | 实现多个选项间的逻辑 or 关系 |
| -E | 支持扩展正则表达式 |
| -f | 从文件获取 PATTERN 匹配 |
| -F | 匹配固定字符串的内容 |
| -h | 搜索多文件时不显示文件名 |
| -i | 忽略关键词大小写 |
| -l | 只显示符合匹配条件的文件名 |
| -n | 显示所有匹配行及其行号 |
| -o | 显示匹配词距文件头部的偏移量 |
| -q | 静默执行模式 |
| -r | 递归搜索模式 |
| -s | 不显示没有匹配文本的错误信息 |
| -v | 显示不包含匹配文本的所有行,==相当于[^] 反向匹配== |
| -w | 精准匹配整词 |
| -x | 精准匹配整行 |
| -A <行数 x> | 除了显示符合范本样式的那一列之外,并显示该行之后的 x 行内容。 |
| -B <行数 x> | 除了显示符合样式的那一行之外,并显示该行之前的 x 行内容 |
| -C<行数 x> | 除了显示符合样式的那一行之外,并显示该行之前后的 x 行内容 |
sed
功能
用于利用语法/脚本对文本文件进行批量的编辑操作
sed 会根据脚本命令来处理文本文件中的数据,这些命令要么从命令行中输入,要么存储在一个文本文件中,此命令执行数据的顺序如下:
- 每次==仅读取一行==内容;
- 根据提供的规则命令匹配并修改数据。注意,sed ==默认不会直接修改源文件数据==,而是会将数据复制到缓冲区中,修改也仅限于缓冲区中的数据;
- 将执行结果输出。
当一行数据匹配完成后,它会继续读取下一行数据,并重复这个过程,直到将文件中所有数据处理完毕。
语法
1 | sed [选项] [脚本命令] 文件名 |
选项
| 参数 | 含义 |
|---|---|
| -e | 使用指定脚本来处理输入的文本文件 以选项中指定的 script 来处理输入的文本文件,这个 -e可以省略,直接写表达式。 |
| -f | 使用指定脚本文件处理输入的文本文件 |
| -h | 显示帮助信息 |
| -i | 直接修改文件内容,而不输出到终端 |
| -n | 仅显示脚本处理后的结果 默认情况下,sed 会在所有的脚本指定执行完毕后,会自动输出处理后的内容,而该选项会屏蔽启动输出,需使用 print 命令来完成输出。 |
| –quiet | 仅显示脚本处理后的结果 |
| –silent | 仅显示脚本处理后的结果 |
| -r | 支持扩展正则表达式 |
| -V | 显示版本信息 |
动作说明
| 动作 | 说明 |
|---|---|
| a | 新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~ |
| c | 取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行! |
| d | 删除,因为是删除啊,所以 d 后面通常不接任何咚咚; |
| i | 插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行); |
| p | 打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~ |
| s | 取代,通常这个 s 的动作可以搭配正规表示法,例如 1,20s/old/new/g 。 |
sed脚本命令
sed s 替换脚本命令
基本格式
1 | [address]s/pattern/replacement/flags |
- address 表示指定要操作的具体行
- pattern 指的是需要替换的内容
- replacement 指的是要替换的新内容
常用的 flags 标记
| flags 标记 | 功能 |
|---|---|
| n | 1~512 之间的数字,表示指定要替换的字符串出现第几次时才进行替换,例如,一行中有 3 个 A,但用户只想替换第二个 A,这是就用到这个标记; |
| g | 对数据中所有匹配到的内容进行替换,如果没有 g,则只会在第一次匹配成功时做替换操作。例如,一行数据中有 3 个 A,则只会替换第一个 A; |
| p | 会打印与替换命令中指定的模式匹配的行。此标记通常与 -n 选项一起使用。 |
| w file | 将缓冲区中的内容写到指定的 file 文件中; |
| & | 用正则表达式匹配的内容进行替换; |
| \n | 匹配第 n 个子串,该子串之前在 pattern 中用 () 指定。 |
| \ | 转义(转义替换部分包含:&、\ 等)。 |
注意
替换类似文件路径的字符串会比较麻烦,需要将路径中的正斜线进行转义,如:
1 | sed 's/\/bin\/bash/\/bin\/csh/' /etc/passwd |
sed d 替换脚本命令
基本格式
1 | [address]d |
sed a 和 i 脚本命令
- a 命令表示在指定行的后面附加一行
- i 命令表示在指定行的前面插入一行
基本格式
1 | [address]a \新文本内容 |
1 | [address]i \新文本内容 |
多行
如果你想将一个多行数据添加到数据流中,只需对要插入或附加的文本中的每一行末尾(除最后一行)添加反斜线即可
sed c 替换脚本命令
c 命令表示将指定行中的所有内容,替换成该选项后面的字符串。该命令的基本格式为:
1 | [address]c\用于替换的新文本 |
sed y 转换脚本命令
y 转换命令是唯一可以处理单个字符的 sed 脚本命令,其基本格式如下:
1 | [address]y/inchars/outchars/ |
转换命令会对 inchars 和 outchars 值进行一对一的映射,即 inchars 中的第一个字符会被转换为 outchars 中的第一个字符,第二个字符会被转换成 outchars 中的第二个字符…这个映射过程会一直持续到处理完指定字符。如果 inchars 和 outchars 的长度不同,则 sed 会产生一条错误消息。
sed p 打印脚本命令
p 命令表示搜索符号条件的行,并输出该行的内容,此命令的基本格式为:
1 | [address]p |
sed w 脚本命令
w 命令用来将文本中指定行的内容写入文件中,此命令的基本格式如下:
1 | [address]w filename |
这里的 filename 表示文件名,可以使用相对路径或绝对路径,但不管是哪种,运行 sed 命令的用户都必须有文件的写权限。
sed r 脚本命令
r 命令用于将一个独立文件的数据插入到当前数据流的指定位置,该命令的基本格式为:
1 | [address]r filename |
sed 命令会将 filename 文件中的内容插入到 address 指定行的后面
sed q 退出脚本命令
q 命令的作用是使 sed 命令在第一次匹配任务结束后,退出 sed 程序,不再进行对后续数据的处理。
sed 脚本命令的寻址方式
对各个脚本命令来说,address 用来表明该脚本命令作用到文本中的具体行
默认情况下,sed 命令会作用于文本数据的所有行。如果只想将命令作用于特定行或某些行,则必须写明 address 部分,表示的方法有以下 2 种:
- 以数字形式指定行区间;
- 用文本模式指定具体行区间。
以上两种形式==都可以使用如下这 2 种格式==,分别是:
1 | [address]脚本命令 |
或者
1 | address { |
例如:
1 | $ sed -n '/3/{ |
以数字形式指定行区间
当使用数字方式的行寻址时,可以用行在文本流中的行位置来引用。sed 会将文本流中的第一行编号为 1,然后继续按顺序为接下来的行分配行号。
在脚本命令中,指定的地址可以是 单个行号,或是 用起始行号、逗号以及结尾行号指定的一定区间范围内的行
用文本模式指定行区间
sed 允许指定文本模式来过滤出命令要作用的行,格式如下:
1 | /pattern/command |
注意,必须用正斜线将要指定的 pattern 封起来,sed 会将该命令作用到包含指定文本模式的行上。
sed 允许在文本模式==使用正则表达式指明作用的具体行==
sed 多行命令
- Next 命令(N):将数据流中的下一行加进来创建一个多行组来处理。
- Delete(D):删除多行组中的一行。
- Print(P):打印多行组中的一行。
注意,以上命令的缩写,都为大写。
awk
和 sed 命令类似,awk 命令也是逐行扫描文件(从第 1 行到最后一行),寻找含有目标文本的行,如果匹配成功,则会在该行上执行用户想要的操作;反之,则不对行做任何处理。
awk 命令的基本格式为
1 | awk [选项] '脚本命令' 文件名 |
awk 命令选项以及含义
| 选项 | 含义 |
|---|---|
| -F fs | 指定以 fs 作为输入行的分隔符,awk 命令默认分隔符为空格或制表符。 |
| -f file | 从脚本文件中读取 awk 脚本指令,以取代直接在命令行中输入指令。 |
| -v var=val | 在执行处理过程之前,设置一个变量 var,并给其设备初始值为 val。 |
脚本命令
awk 的强大之处在于脚本命令,它由 2 部分组成,分别为匹配规则和执行命令,如下所示
1 | '匹配规则{执行命令}' |
匹配规则
和 sed 命令中的 address 部分作用相同:用来指定脚本命令可以作用到文本内容中的具体行,可以使用字符串(比如 /demo/,表示查看含有 demo 字符串的行)或者正则表达式指定
注意
- 整个==脚本命令是用单引号(’’)括起==,而其中的==执行命令部分需要用大括号({})括起来==
- 在 awk 程序执行时,如果没有指定执行命令,则==默认会把匹配的行输出==;如果不指定匹配规则,则==默认匹配文本中所有的行==
awk 使用数据字段变量
awk 的主要特性之一是其处理文本文件中数据的能力,它会自动给一行中的每个数据元素分配一个变量。
默认情况下,awk 会将如下变量分配给它在文本行中发现的数据字段:
| 变量 | 数据字段 |
|---|---|
$0 |
代表整个文本行; |
$1 |
代表文本行中的第 1 个数据字段; |
$2 |
代表文本行中的第 2 个数据字段; |
$n |
代表文本行中的第 n 个数据字段。 |
在 awk 中,==默认的字段分隔符是任意的空白字符==(例如空格或制表符)。 在文本行中,每个数据字段都是通过字段分隔符划分的。awk 在读取一行文本时,会用预定义的字段分隔符划分每个数据字段。
awk 脚本命令使用多个命令
方法1
awk 允许将多条命令组合成一个正常的程序。要在命令行上的程序脚本中使用多条命令,只要在命令之间放个分号即可,例如:
1 | echo "My name is Rich" | awk '{$4="Christine"; print $0}' |
第一条命令会给字段变量 $4 赋值。第二条命令会打印整个数据字段。
方法2
可以一次一行地输入程序脚本命令,比如说:
1 | echo "My name is Rich" | awk '{ |
在你用了表示起始的单引号后,bash shell 会使用 > 来提示输入更多数据,我们可以每次在每行加一条命令,直到输入了结尾的单引号。
awk从文件中读取程序
跟 sed 一样,awk 允许将脚本命令存储到文件中,然后再在命令行中引用,比如:
1 | awk -F : -f awk.sh /etc/passwd |
注意,在程序文件中,也可以指定多条命令,==只要一条命令放一行即可,之间不需要用分号==。
awk BEGIN关键字
awk 中还可以指定脚本命令的运行时机。默认情况下,awk 会从输入中读取一行文本,然后针对该行的数据执行程序脚本,但有时可能需要==在处理数据前运行一些脚本命令==,这就需要使用 BEGIN 关键字。
BEGIN 会强制 awk 在读取数据前执行该关键字后指定的脚本命令
例如:
1 | awk 'BEGIN {print "The data3 File Contents:"} |
BEGIN 部分的脚本指令会在 awk 命令处理数据前运行,而真正用来处理数据的是第二段脚本命令。
awk END关键字
和 BEGIN 关键字相对应,END 关键字允许我们指定一些脚本命令,awk 会在==读完数据后执行它们==,例如:
1 | awk 'BEGIN {print "The data3 File Contents:"} |
当 awk 程序打印完文件内容后,才会执行 END 中的脚本命令。
awk 使用变量
在 awk 的脚本程序中,支持使用变量来存取值。awk 支持两种不同类型的变量:
- 内建变量:awk 本身就创建好,用户可以直接拿来用的变量,这些变量用来存放处理数据文件中的某些字段和记录的信息。
- 自定义变量:awk 支持用户自己创建变量。
内建变量
awk 程序使用内建变量来引用程序数据里的一些特殊功能
| 变量 | 功能 |
|---|---|
$0 |
代表整个文本行; |
$1 |
代表文本行中的第 1 个数据字段; |
$2 |
代表文本行中的第 2 个数据字段; |
$n |
代表文本行中的第 n 个数据字段。 |
FIELDWIDTHS |
由空格分隔的一列数字,定义了每个数据字段的确切宽度。 一旦设定了 FIELDWIDTHS 变量的值,就不能再改变了,因此,这种方法并==不适用于变长的字段== |
FNR |
当前输入文档的记录编号,常在有多个输入文档时使用。 |
NR |
输入流的当前记录编号。 |
FS |
输入字段分隔符 |
RS |
输入记录分隔符,默认为换行符 \n。 |
OFS |
输出字段分隔符,默认为空格。 print 命令会自动将 OFS 变量的值放置在输出中的每个字段间 |
ORS |
输出记录分隔符,默认为换行符 \n。 |
ARGC |
命令行参数个数。 |
ARGIND |
当前文件在 ARGC 中的位置。 |
ARGV |
包含命令行参数的数组。 |
CONVFMT |
数字的转换格式,默认值为 %.6g。 |
ENVIRON |
当前 shell 环境变量及其值组成的关联数组。 |
ERRNO |
当读取或关闭输入文件发生错误时的系统错误号。 |
FILENAME |
当前输入文档的名称。 |
FNR |
==当前数据文件==中的数据行数。 |
IGNORECASE |
设成非 0 值时,忽略 awk 命令中出现的字符串的字符大小写。 |
NF |
数据文件中的字段总数。 |
NR |
已处理的输入记录==总数==。会持续计数直到处理完所有的数据文件 |
OFMT |
数字的输出格式,默认值为 %.6g。 |
RLENGTH |
由 match 函数所匹配的子字符串的长度。 |
TSTART |
由 match 函数所匹配的子字符串的起始位置。 |
理解
- 字段分隔符:作用于 awk 每次处理的一个单元
- 记录分隔符:用于区分 awk 每次要处理的一个单元
自定义变量
awk 允许用户定义自己的变量在脚本程序中使用。awk 自定义变量名可以是任意数目的字母、数字和下划线,但不能以数字开头。更重要的是,awk 变量名==区分大小写==
也可以用 awk 命令行来给程序中的变量赋值,这允许我们在正常的代码之外赋值,即时改变变量的值,比如:
1 | [root@localhost ~]# awk ' |
需要注意的是,使用命令行参数来定义变量值会有一个问题,即设置了变量后,这个值在代码的 BEGIN 部分不可用,如下所示:
1 | [root@localhost ~]$ cat script2 |
解决这个问题,可以用 -v 命令行参数,它可以实现在 BEGIN 代码之前设定变量。在命令行上,-v 命令行参数必须放在脚本代码之前,如下所示:
1 | [root@localhost ~]$ awk -v n=3 -f script2 data1 |
awk 使用数组
awk 使用分支结构
awk 使用循环结构
awk 使用函数
wget
wget是一个命令行的下载工具。对于我们这些 Linux 用户来说,几乎每天都在使用它。下面为大家介绍几个有用的 wget 小技巧,可以让你更加高效而灵活的使用 wget。
1 | $ wget -r -np -nd http://example.com/packages/ |
这条命令可以下载 http://example.com 网站上 packages 目录中的所有文件。其中,-np的作用是不遍历父目录,-nd表示不在本机重新创建目录结构。
1 | $ wget -r -np -nd --accept=iso http://example.com/centos-5/i386/ |
与上一条命令相似,但多加了一个–accept=iso选项,这指示 wget 仅下载 i386 目录中所有扩展名为 iso 的文件。你也可以指定多个扩展名,只需用逗号分隔即可。
1 | $ wget -i filename.txt |
此命令常用于批量下载的情形,把所有需要下载文件的地址放到 filename.txt 中,然后 wget 就会自动为你下载所有文件了。
1 | $ wget -c http://example.com/really-big-file.iso |
这里所指定的-c选项的作用为断点续传。
1 | $ wget -m -k (-H) http://www.example.com/ |
该命令可用来镜像一个网站,wget 将对链接进行转换。如果网站中的图像是放在另外的站点,那么可以使用-H选项。