面向对象基础 例子 1 2 3 4 class Person { public String name; public int age; }
一个 class 可以包含多个字段(field),字段用来描述一个类的特征。上面的 Person 类,我们定义了两个字段,一个是 String 类型的字段,命名为 name,一个是 int 类型的字段,命名为 age。因此,通过 class,把一组数据汇集到一个对象上,实现了数据封装。
字段就是 C++ 中的成员属性
创建实例 1 Person ming = new Person ();
实例化 1 2 3 Role role1 = new Role (); Role role2; role2 = new Role ();
类和对象的关系
类是一个抽象的概念,仅仅是模板,比如说:演员、总统
对象是一个你能够看得到、摸得着的具体实体
类的定义者和类的使用者是不一样的。越往下越具体,越往上越抽象。
基本步骤
发现类
找出属性(名词)
找出行为(动词)
数据抽象:是数据和处理方法的结合
小结
在 OOP 中,class 和 instance 是 “模版” 和 “实例” 的关系;
类就是对象的模板(蓝图)
定义 class 就是定义了一种数据类型,对应的 instance 是这种数据类型的实例;
class 定义的 field,在每个 instance 都会拥有各自的 field,且互不干扰;
通过 new 操作符创建新的 instance,然后用变量指向它,即可通过变量来引用这个 instance;
访问实例字段的方法是变量名. 字段名;
类图
直观、容易理解
参考工具:
StarUML
Astah
属性名在前,后面跟冒号和类型名
方法名在前,后面跟冒号和返回值类型
如果有参数,参数的类型写法同上
Astah
方法 把 field 从 public 改成 private,外部代码不能访问这些 field,以我们需要使用方法(method)来让外部代码可以间接修改 field:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 public class Main { public static void main (String[] args) { Person ming = new Person (); ming.setName("Xiao Ming" ); ming.setAge(12 ); System.out.println(ming.getName() + "," + ming.getAge()); } } class Person { private String name; private int age; public String getName () { return this .name; } public void setName (String name) { this .name = name; } public int getAge () { return this .age; } public void setAge (int age) { if (age < 0 || age> 100 ) { throw new IllegalArgumentException ("invalid age value" ); } this .age = age; } }
虽然外部代码不能直接修改 private 字段,但是,外部代码可以调用方法 setName() 和 setAge() 来间接修改 private 字段。在方法内部,我们就有机会检查参数对不对。比如,setAge() 就会检查传入的参数,参数超出了范围,直接报错。这样,外部代码就没有任何机会把 age 设置成不合理的值。
调用方法的语法是实例变量 . 方法名 (参数);。一个方法调用就是一个语句,所以不要忘了在末尾加 ;。例如:ming.setName("Xiao Ming");。
定义方法 1 2 3 4 修饰符 方法返回类型 方法名 (方法参数列表) { 若干方法语句; return 方法返回值;}
private 方法
有 public 方法,自然就有 private 方法。和 private 字段一样,private 方法不允许外部调用,定义 private 方法的理由是内部方法是可以调用 private 方法的。
this 变量
在方法内部,可以使用一个隐含的变量 this,它始终指向当前实例。因此,通过 this.field 就可以访问当前实例的字段。如果没有命名冲突,可以省略 this,但是如果有局部变量和字段重名,那么局部变量优先级更高,就必须加上 this
方法参数
方法可以包含 0 个或任意个参数。方法参数用于接收传递给方法的变量值。调用方法时,必须严格按照参数的定义一一传递。(同 C++)
可变参数
可变参数用 类型... 定义,可变参数相当于数组类型:1 2 class Group { private String[] names;
public void setNames(String... names) {
this.names = names;
}
}1 2 3 4 5 6 7 > 上面的 setNames() 就定义了一个可变参数。调用时,可以这么写: ```java Group g = new Group(); g.setNames("Xiao Ming", "Xiao Hong", "Xiao Jun"); // 传入 3 个 String g.setNames("Xiao Ming", "Xiao Hong"); // 传入 2 个 String g.setNames("Xiao Ming"); // 传入 1 个 String g.setNames(); // 传入 0 个 String
完全可以把可变参数改写为 String[] 类型:1 2 class Group { private String[] names;
public void setNames(String[] names) {
this.names = names;
}
}1 2 3 4 > 但是,调用方需要自己先构造 String[],比较麻烦。例如: ```java Group g = new Group(); g.setNames(new String[] {"Xiao Ming", "Xiao Hong", "Xiao Jun"}); // 传入 1 个 String[]
另一个问题是,调用方可以传入 null:
1 2 Group g = new Group ();g.setNames(null );
而可变参数可以保证无法传入 null,因为传入 0 个参数时,接收到的实际值是一个空数组而不是 null。
参数绑定
传参的问题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class Main { public static void main (String[] args) { Person p = new Person (); String[] fullname = new String [] { "Homer" , "Simpson" }; p.setName(fullname); System.out.println(p.getName()); fullname[0 ] = "Bart" ; System.out.println(p.getName()); } } class Person { private String[] name; public String getName () { return this .name[0 ] + " " + this .name[1 ]; } public void setName (String[] name) { this .name = name; } }
Note : 因为传入的是字符串数组,因此将 fullname 数组的地址复制,传给了 p.name,因此 p.name 和 fullname 指向的是同一个字符串数组,所以这两个同时变化,但是变化的时候还是遵循引用的原则:Homer 仍然存在,只是无法通过 fullname[0] 进行访问罢了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class Main { public static void main (String[] args) { Person p = new Person (); String bob = "Bob" ; p.setName(bob); System.out.println(p.getName()); bob = "Alice" ; System.out.println(p.getName()); } } class Person { private String name; public String getName () { return this .name; } public void setName (String name) { this .name = name; } }
Note : 和上一个传入引用参数一样,复制的是地址,传入之后 bob 和 p.name 指向了同一块内存,只不过 bob 改变之后会重新指向新的内存,所以这两个变量指向的内存就不一样了。
Note :字符串和数组都是引用类型。
构造方法
由于构造方法是如此特殊,所以构造方法的名称就是类名。构造方法的参数没有限制,在方法内部,也可以编写任意语句。但是,和普通方法相比,构造方法没有返回值(也没有 void),调用构造方法,必须用 new 操作符。(具体意义和 C++ 一样)
没有在构造方法中初始化字段时,引用类型的字段默认是 null,数值类型的字段用默认值,int 类型默认值是 0,布尔类型默认值是 false:
可以对字段直接进行初始化:
1 2 3 4 5 6 7 8 9 class Person { private String name = "Unamed" ; private int age = 10 ; public Person (String name, int age) { this .name = name; this .age = age; } }
构造方法的代码由于后运行,最终由构造方法的代码确定,即便已经直接将字段初始化了。
方法重载 > 同 C++
继承 Student 类包含了 Person 类已有的字段和方法,只是多出了一个 score 字段和相应的 getScore()、setScore() 方法。
实现
Java 使用 extends 关键字来实现继承:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Person { private String name; private int age; public String getName () {...} public void setName (String name) {...} public int getAge () {...} public void setAge (int age) {...} } class Student extends Person { private int score; public int getScore () { …} public void setScore (int score) { … } }
通过继承,Student 只需要编写额外的功能,不再需要重复代码。
Note: 子类自动获得了父类的所有字段,严禁定义与父类重名的字段!
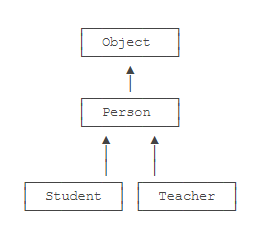
在 OOP 的术语中,我们把 Person 称为 超类(super class), 父类(parent class), 基类(base class),把 Student 称为 子类(subclass), 扩展类(extended class)。
继承树 在 Java 中,没有明确写 extends 的类,编译器会自动加上 extends Object。所以,任何类,除了 Object,都会继承自某个类。
例如:
protected 继承有个特点,就是子类无法访问父类的 private 字段或者 private 方法。private 改为 protected。用 protected 修饰的字段可以被子类访问: 因此,protected 关键字可以把字段和方法的访问权限控制在继承树内部,一个 protected 字段和方法可以被其子类,以及子类的子类所访问。
super super 关键字表示父类(超类)。子类引用父类的字段时,可以用 super.fieldName。例如:
1 2 3 4 5 class Student extends Person { public String hello () { return "Hello," + super .name; } }
实际上,这里使用 super.name,或者 this.name,或者 name,效果都是一样的。编译器会自动定位到父类的 name 字段。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public class Main { public static void main (String[] args) { Student s = new Student ("Xiao Ming" , 12 , 89 ); } } class Person { protected String name; protected int age; public Person (String name, int age) { this .name = name; this .age = age; } } class Student extends Person { protected int score; public Student (String name, int age, int score) { this .score = score; } }
运行上面的代码,会得到一个 编译错误 ,大意是在 Student 的构造方法中,无法调用 Person 的构造方法。
这是因为在 Java 中,任何 class 的构造方法,**第一行语句必须是调用父类的构造方法。如果没有明确地调用父类的构造方法,编译器会帮我们自动加一句 super();**,所以,Student 类的构造方法实际上是这样:
1 2 3 4 5 6 7 8 class Student extends Person { protected int score; public Student (String name, int age, int score) { super (); this .score = score; } }
但是,Person 类并没有无参数的构造方法,因此,编译失败。
解决方法是调用 Person 类存在的某个构造方法。例如:
1 2 3 4 5 6 7 8 class Student extends Person { protected int score; public Student (String name, int age, int score) { super (name, age); this .score = score; } }
如果父类没有默认的构造方法,子类就必须显式调用 super() 并给出参数以便让编译器定位到父类的一个合适的构造方法。
这里还顺带引出了另一个问题:即子类不会继承任何父类的构造方法。子类默认的构造方法是编译器自动生成的,不是继承的。
阻止继承 只要某个 class 没有 final 修饰符,那么任何类都可以从该 class 继承。sealed 修饰 class,并通过 permits 明确写出能够从该 class 继承的子类名称。
1 2 3 public sealed class Shape permits Rect, Circle, Triangle { ... }
上述 Shape 类就是一个 sealed 类,它只允许指定的 3 个类 (Rect, Circle, Triangle) 继承它,否则就会报错。sealed 类主要用于一些框架,防止继承被滥用。sealed 类在 Java 15 中目前是预览状态,要启用它,必须使用参数 --enable-preview 和 --source 15。
向上转型:一个子类类型安全地变为父类类型的赋值 向上转型实际上是把一个子类型安全地变为更加抽象的父类型1 2 3 4 Student s = new Student ();Person p = s; Object o1 = p; Object o2 = s;
p 也只能使用 Person 类中有的字段和方法,不能使用 Student 添加的字段和方法
向下转型:把一个父类类型强制转型为子类类型 不能把父类变为子类,因为子类功能比父类多,多的功能无法凭空变出来。
instanceof 实际上判断一个变量所指向的实例是否是指定类型,或者这个类型的子类。如果一个引用变量为 null,那么对任何 instanceof 的判断都为 false。
1 2 3 4 5 Person p = new Student ();if (p instanceof Student) { Student s = (Student) p; }
从 Java 14 开始,判断 instanceof 后,可以直接转型为指定变量,避免再次强制转型。
1 2 3 4 5 6 7 8 9 public class Main { public static void main (String[] args) { Object obj = "hello" ; if (obj instanceof String s) { System.out.println(s.toUpperCase()); } } }
等价于1 2 3 4 5 Object obj = "hello" ;if (obj instanceof String) { String s = (String) obj; System.out.println(s.toUpperCase()); }
组合和继承 1 2 3 4 5 class Book { protected String name; public String getName () {...} public void setName (String name) {...} }
这个 Book 类也有 name 字段,那么,我们能不能让 Student 继承自 Book 呢?不可以
1 2 3 4 class Student extends Person { protected Book book; protected int score; }
继承是 is 关系,组合是 has 关系。
多态 补充 方法签名由方法名称和一个参数列表(方法的参数的顺序和类型)组成。
Note :方法签名不包括方法的返回类型。不包括返回值和访问修饰符。
覆写(重写、覆盖)
在继承关系中,子类如果定义了一个与父类方法签名完全相同的方法,被称为覆写(Override)。
重写(Override)和重载(Overload)
重写: 前提是继承,两个方法的方法签名相同。至于修饰符,范围相同或者比父类的范围大即可。
要是重写的话,也不是必须加 @override,写 @override,这个表示编辑器会给你去父类检查重写的对不对,不写就自己检查呗。
重写是覆盖,就是子类的替换了父类的,正常用方法,调的是子类的,所以重写完还是一个方法
注意
父类:如果是 private,那么子类就不存在重写,只是新建了个方法。但是要是 protected 的话,子类就可以重写。@override 是可以 OK 的。子类是 protected 或者 public,不可以是 private(经测试 private 类型是错误的,直接报错)。
在修饰符条件 OK 的情况下,发现如果可继承的要重写的方法要是返回类型不同,编辑器也是会报错的。说是重写的两个方法的返回类型冲突、不相容的,矛盾的返回类型。
引例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class Main { public static void main (String[] args) { Person p = new Student (); p.run(); } } class Person { public void run () { System.out.println("Person.run" ); } } class Student extends Person { @Override public void run () { System.out.println("Student.run" ); } }
Java 的实例方法调用是基于运行时的实际类型的动态调用,而非变量的声明类型。
多态定义
针对某个类型的方法调用,其真正执行的方法取决于运行时期实际类型的方法。1 2 3 public void runTwice (Person p) { p.run(); }
多态的用处
我们要编写一个报税的财务软件,对于一个人的所有收入进行报税1 2 3 4 5 6 7 8 9 10 public class Main { public static void main (String[] args) { Income[] incomes = new Income [] { new Income (3000 ), new Salary (7500 ), new StateCouncilSpecialAllowance (15000 ) }; System.out.println(totalTax(incomes)); }
public static double totalTax(Income... incomes) {
double total = 0;
for (Income income: incomes) {
total = total + income.getTax();
}
return total;
}
}
class Income {
public Income(double income) {
this.income = income;
}
public double getTax() {
return income * 0.1; // 税率 10%
}
}
class Salary extends Income {
@Override
public double getTax() {
if (income <= 5000) {
return 0;
}
return (income - 5000) * 0.2;
}
}
class StateCouncilSpecialAllowance extends Income {
@Override
public double getTax() {
return 0;
}
}1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 > 观察 totalTax() 方法:利用多态,totalTax() 方法只需要和 Income 打交道,它完全不需要知道 Salary 和 StateCouncilSpecialAllowance 的存在,就可以正确计算出总的税。如果我们要新增一种稿费收入,只需要从 Income 派生,然后正确覆写 getTax() 方法就可以。把新的类型传入 totalTax(),不需要修改任何代码。 > *** 可见,多态具有一个非常强大的功能,就是允许添加更多类型的子类实现功能扩展,却不需要修改基于父类的代码。*** ## 调用 super ```java class Person { protected String name; public String hello() { return "Hello," + name; } } Student extends Person { @Override public String hello() { // 调用父类的 hello() 方法: return super.hello() + "!"; } }
final
继承可以允许子类覆写父类的方法。如果一个父类不允许子类对它的某个方法进行覆写,可以把该方法标记为 final。用 final 修饰的方法不能被 Override:1 2 3 4 5 6 7 8 9 10 11 12 13 class Person { protected String name; public final String hello () { return "Hello," + name; } } Student extends Person { @Override public String hello () { } }
如果一个类不希望任何其他类继承自它,那么可以把这个类本身标记为 final。用 final 修饰的类不能被继承:1 2 3 4 5 6 7 final class Person { protected String name; } Student extends Person { }
对于一个类的实例字段,同样可以用 final 修饰。用 final 修饰的字段在初始化后不能被修改。1 2 3 class Person { public final String name = "Unamed" ; }
1 2 Person p = new Person ();p.name = "New Name" ;
1 2 3 4 5 6 7 public class Person { public final String name = "Unamed" ; public TestDemo1 (String name) { this .name = name; } }
1 2 3 4 5 6 class Person { public final String name; public Person (String name) { this .name = name; } }
因为可以保证实例一旦创建,其 final 字段就不可修改:
抽象类 引入
因为可以保证实例一旦创建,其 final 字段就不可修改:1 2 3 class Person { public void run () { …} }
class Student extends Person {
class Teacher extends Person {1 2 3 4 5 6 > 从 Person 类派生的 Student 和 Teacher 都可以覆写 run() 方法。 > 如果父类 Person 的 run() 方法没有实际意义,能否去掉方法的执行语句? ```java class Person { public void run(); // Compile Error! }
答案是不行,会导致编译错误,因为定义方法的时候,必须实现方法的语句。run() 方法,因为如果去掉了父类的 run() 方法,就会失去多态的特性
解决办法:如果父类的方法本身不需要实现任何功能,仅仅是为了定义方法签名,目的是让子类去覆写它,那么,可以把父类的方法声明为抽象方法:1 2 3 class Person { public abstract void run () ; }
abstract,才能正确编译它:1 2 3 abstract class Person { public abstract void run () ; }
个人理解 1 2 3 abstract class Person { public abstract void run () ; }
等价于1 2 3 class Person { public void run () {} }
区别在于:
定义
如果一个 class 定义了方法,但没有具体执行代码,这个方法就是抽象方法,抽象方法用 abstract 修饰。
使用 abstract 修饰的类就是抽象类。我们无法实例化一个抽象类:
1 Person p = new Person ();
抽象类的用途
因为抽象类本身被设计成只能用于被继承,因此,抽象类可以强迫子类实现其定义的抽象方法,否则编译会报错。因此,抽象方法实际上相当于定义了 “规范”。
例如,Person 类定义了抽象方法 run(),那么,在实现子类 Student 的时候,就必须覆写 run() 方法:
面向抽象编程
当我们定义了抽象类 Person,以及具体的 Student、Teacher 子类的时候,我们可以通过抽象类 Person 类型去引用具体的子类的实例:1 2 Person s = new Student ();Person t = new Teacher ();
1 2 3 Person e = new Employee ();e.run();
这种尽量引用 ** 高层类型 **(相当于父类),避免引用 ** 实际子类型 **(相当于子类)的方式,称之为面向抽象编程。
面向抽象编程的本质就是:
上层代码只定义规范(例如:abstract class Person);
不需要子类就可以实现业务逻辑(正常编译);
具体的业务逻辑由不同的子类实现,调用者并不关心(个人理解:就是调用者只需要知道抽象类有什么字段和方法以及功能,不关心具体怎么实现的,可以直接调用,具体实现对调用者透明)。
小结
通过 abstract 定义的方法是抽象方法,它只有定义,没有实现。抽象方法定义了子类必须实现的接口规范;
定义了抽象方法的 class 必须被定义为抽象类,从抽象类继承的子类必须实现抽象方法;
如果不实现抽象方法,则该子类仍是一个抽象类;
面向抽象编程使得调用者只关心抽象方法的定义,不关心子类的具体实现。
接口 引入
在抽象类中,抽象方法本质上是定义接口规范:即规定高层类的接口,从而保证所有子类都有相同的接口实现,这样,多态就能发挥出威力。
如果一个抽象类没有字段,所有方法全部都是抽象方法:1 2 3 4 abstract class Person { public abstract void run () ; public abstract String getName () ; }
interface 。1 2 3 4 interface Person { void run () ; String getName () ; }
定义
所谓 interface,就是比抽象类还要抽象的纯抽象接口,因为它连字段都不能有。因为接口定义的所有方法默认都是 public abstract 的,所以这两个修饰符不需要写出来(写不写效果都一样)。
当一个具体的 class 去实现一个 interface 时,需要使用 implements 关键字。举个例子:1 2 class Student implements Person { private String name;
public Student(String name) {
this.name = name;
}
@Override
public void run() {
System.out.println(this.name + "run");
}
@Override
public String getName() {
return this.name;
}
}1 2 3 4 5 > 在 Java 中,一个类只能继承自另一个类,不能从多个类继承。但是,一个类可以实现多个 interface,例如: ```java class Student implements Person, Hello { // 实现了两个 interface ... }
术语
Java 的接口特指 interface 的定义,表示一个接口类型和一组方法签名,而编程接口泛指接口规范,如方法签名,数据格式,网络协议等。
抽象类和接口的对比如下:
abstract
class
interface
继承
只能 extends 一个 class
可以 implements 多个 interface
字段
可以定义实例字段
不能定义实例字段
抽象方法
可以定义抽象方法
可以定义抽象方法
非抽象方法
可以定义非抽象方法
可以定义 default 方法
接口继承
一个 interface 可以继承自另一个 interface。interface 继承自 interface 使用 extends,它相当于扩展了接口的方法。例如:
1 2 3 4 5 6 7 8 9 10 interface Hello { void hello () ; } interface Person extends Hello { void run () ; String getName () ; }
此时,Person 接口继承自 Hello 接口,因此,Person 接口现在实际上有 3 个抽象方法签名,其中一个来自继承的 Hello 接口。
继承关系 合理设计 interface 和 abstract class 的继承关系,可以充分复用代码。一般来说,公共逻辑适合放在 abstract class 中,具体逻辑放到各个子类,而接口层次代表抽象程度。可以参考 Java 的集合类定义的一组接口、抽象类以及具体子类的继承关系:
在使用的时候,实例化的对象永远只能是某个具体的子类,但总是通过接口去引用它,因为接口比抽象类更抽象:
1 2 3 List list = new ArrayList (); Collection coll = list; Iterable it = coll;
default 方法
在接口中,可以定义 default 方法。例如,把 Person 接口的 run() 方法改为 default 方法:1 2 3 4 5 6 public class Main { public static void main (String[] args) { Person p = new Student ("Xiao Ming" ); p.run(); } }
interface Person {
class Student implements Person {
public Student(String name) {
this.name = name;
}
public String getName() {
return this.name;
}
}1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 > 实现类可以不必覆写 default 方法。default 方法的目的是,当我们需要给接口新增一个方法时,会涉及到修改全部子类。如果新增的是 default 方法,那么子类就不必全部修改,只需要在需要覆写的地方去覆写新增方法。 > default 方法和抽象类的普通方法是有所不同的。因为 interface 没有字段,default 方法无法访问字段,而抽象类的普通方法可以访问实例字段。 ## 小结 - Java 的接口(interface)定义了纯抽象规范,一个类可以实现多个接口; - 接口也是数据类型,适用于向上转型和向下转型; - 接口的所有方法都是抽象方法,接口不能定义实例字段; - 接口可以定义 default 方法(JDK>=1.8)。 # 静态字段和静态方法 ## 静态字段 > 在一个 class 中定义的字段,我们称之为实例字段。实例字段的特点是,每个实例都有独立的字段,各个实例的同名字段互不影响。 > 还有一种字段,是用 static 修饰的字段,称为静态字段:static field。 > 实例字段在每个实例中都有自己的一个独立 “空间”,但是静态字段只有一个共享 “空间”,所有实例都会共享该字段。举个例子: ```java class Person { public String name; public int age; // 定义静态字段 number: public static int number; }
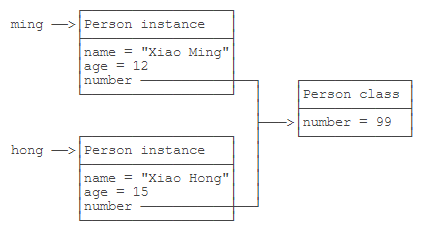
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public class Main { public static void main (String[] args) { Person ming = new Person ("Xiao Ming" , 12 ); Person hong = new Person ("Xiao Hong" , 15 ); ming.number = 88 ; System.out.println(hong.number); hong.number = 99 ; System.out.println(ming.number); } } class Person { public String name; public int age; public static int number; public Person (String name, int age) { this .name = name; this .age = age; } }
输出
对于静态字段,无论修改哪个实例的静态字段,效果都是一样的:所有实例的静态字段都被修改了,原因是静态字段并不属于实例:Person class 的静态字段。所以,所有实例共享一个静态字段。实例变量. 静态字段 去访问静态字段,因为在 Java 程序中,实例对象并没有静态字段。在代码中,实例对象能访问静态字段只是因为编译器可以根据实例类型自动转换为类名. 静态字段来访问静态对象。
推荐用类名来访问静态字段。可以把静态字段理解为描述 class 本身的字段(非实例字段)。对于上面的代码,更好的写法是:1 2 Person.number = 99 ; System.out.println(Person.number);
静态方法
有静态字段,就有静态方法。用 static 修饰的方法称为静态方法。(废话)1 2 3 4 5 6 public class Main { public static void main (String[] args) { Person.setNumber(99 ); System.out.println(Person.number); } }
class Person {
public static void setNumber(int value) {
number = value;
}
}1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 > 因为静态方法属于 class 而不属于实例,因此,静态方法内部,无法访问 this 变量,也无法访问实例字段,它只能访问静态字段。 > 通过实例变量也可以调用静态方法,但这只是编译器自动帮我们把实例改写成类名而已。 > 通常情况下,通过实例变量访问静态字段和静态方法,会得到一个编译警告。 > 静态方法经常用于工具类,例如: - `Arrays.sort()` - `Math.random()` > 静态方法也经常用于辅助方法。注意到 Java 程序的入口 main() 也是静态方法。 ## 接口的静态字段 > 因为 interface 是一个纯抽象类,所以它不能定义实例字段。但是,interface 是可以有静态字段的,并且静态字段必须为 final 类型: ```java public interface Person { public static final int MALE = 1; public static final int FEMALE = 2; }
实际上,因为 interface 的字段只能是 public static final 类型,所以我们可以把这些修饰符都去掉,上述代码可以简写为:1 2 3 4 5 public interface Person { int MALE = 1 ; int FEMALE = 2 ; }
小结
静态字段属于所有实例 “共享” 的字段,实际上是属于 class 的字段;
调用静态方法不需要实例,无法访问 this,但可以访问静态字段和其他静态方法;
静态方法常用于工具类和辅助方法。
包 定义
在前面的代码中,我们把类和接口命名为 Person、Student、Hello 等简单名字。
在现实中,如果小明写了一个 Person 类,小红也写了一个 Person 类,现在,小白既想用小明的 Person,也想用小红的 Person,怎么办?
如果小军写了一个 Arrays 类,恰好 JDK 也自带了一个 Arrays 类,如何解决类名冲突?
在 Java 中,我们使用 package 来解决名字冲突。
Java 定义了一种名字空间,称之为包:package。一个类总是属于某个包,类名(比如 Person)只是一个简写,真正的完整类名是包名. 类名。
例如:
小明的 Person 类存放在包 ming 下面,因此,完整类名是 ming.Person;
小红的 Person 类存放在包 hong 下面,因此,完整类名是 hong.Person;
小军的 Arrays 类存放在包 mr.jun 下面,因此,完整类名是 mr.jun.Arrays;
JDK 的 Arrays 类存放在包 java.util 下面,因此,完整类名是 java.util.Arrays。
在定义 class 的时候,我们需要在第一行声明这个 class 属于哪个包。
小明的 Person.java 文件
public class Person {
}1 2 3 4 5 6 7 8 > 小军的 `Arrays.java` 文件 ```java package mr.jun; // 申明包名 mr.jun public class Arrays { }
在 Java 虚拟机执行的时候,JVM 只看完整类名,因此,只要包名不同,类就不同。
包可以是多层结构,用 . 隔开。例如:java.util。
要特别注意:包没有父子关系。java.util 和 java.util.zip 是不同的包,两者没有任何继承关系。
没有定义包名的 class,它使用的是默认包,非常容易引起名字冲突,因此,不推荐不写包名的做法。
我们还需要按照包结构把上面的 Java 文件组织起来。假设以 package_sample 作为根目录,src 作为源码目录,那么所有文件结构就是:
1 2 3 4 5 6 7 8 9 package_sample └─ src ├─ hong │ └─ Person.java │ ming │ └─ Person.java └─ mr └─ jun └─ Arrays.java
即所有 Java 文件对应的目录层次要和包的层次一致。
编译后的 .class 文件也需要按照包结构存放。如果使用 IDE,把编译后的 .class 文件放到 bin 目录下,那么,编译的文件结构就是:
1 2 3 4 5 6 7 8 9 package_sample └─ bin ├─ hong │ └─ Person.class │ ming │ └─ Person.class └─ mr └─ jun └─ Arrays.class
编译的命令相对比较复杂,我们需要在 src 目录下执行 javac 命令:1 javac -d ../bin ming/Person.java hong/Person.java mr/jun/Arrays.java
包作用域
位于同一个包的类,可以访问包作用域的字段和方法。不用 public、protected、private 修饰的字段和方法就是包作用域。例如,Person 类定义在 hello 包下面:
public class Person {1 2 3 4 5 6 7 8 9 10 > Main 类也定义在 hello 包下面: ```java package hello; public class Main { public static void main(String[] args) { Person p = new Person(); p.hello(); // 可以调用,因为 Main 和 Person 在同一个包 } }
import
在一个 class 中,我们总会引用其他的 class。例如,小明的 ming.Person 类,如果要引用小军的 mr.jun.Arrays 类,他有三种写法:
第一种,直接写出完整类名,例如:
public class Person {1 2 3 4 5 6 7 8 9 10 11 12 13 14 > 很显然,每次写完整类名比较痛苦。 > 因此,第二种写法是用 import 语句,导入小军的 Arrays,然后写简单类名: ```java // Person.java package ming; // 导入完整类名: import mr.jun.Arrays; public class Person { public void run() { Arrays arrays = new Arrays(); } }
在写 import 的时候,可以使用 *,表示把这个包下面的所有 class 都导入进来(但不包括子包的 class):
// 导入 mr.jun 包的所有 class:
public class Person {1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 > 我们一般不推荐这种写法,因为在导入了多个包后,很难看出 Arrays 类属于哪个包。 > 还有一种 import static 的语法,它可以导入可以导入一个类的静态字段和静态方法: ```java package main; // 导入 System 类的所有静态字段和静态方法: import static java.lang.System.*; public class Main { public static void main(String[] args) { // 相当于调用 System.out.println(…) out.println("Hello, world!"); } }
import static 很少使用。
Java 编译器最终编译出的 .class 文件只使用完整类名,因此,在代码中,当编译器遇到一个 class 名称时:
如果是完整类名,就直接根据完整类名查找这个 class;
如果是简单类名,按下面的顺序依次查找:
查找当前 package 是否存在这个 class;
查找 import 的包是否包含这个 class;
查找 java.lang 包是否包含这个 class。
如果按照上面的规则还无法确定类名,则编译报错。
编写 class 的时候,编译器会自动帮我们做两个 import 动作:
默认自动 import 当前 package 的其他 class;
默认自动 import java.lang.*。
** 注意 **:
自动导入的是 java.lang 包,但类似 java.lang.reflect 这些包仍需要手动导入。
如果有两个 class 名称相同,例如,mr.jun.Arrays 和 java.util.Arrays,那么只能 import 其中一个,另一个必须写完整类名。
最佳实践
为了避免名字冲突,我们需要确定唯一的包名。推荐的做法是使用倒置的域名来确保唯一性。例如:
org.apacheorg.apache.commons.logcom.liaoxuefeng.sample
子包就可以根据功能自行命名。
要注意不要和 java.lang 包的类重名,即自己的类不要使用这些名字:
StringSystemRuntime...
要注意也不要和 JDK 常用类重名:
java.util.Listjava.text.Formatjava.math.BigInteger...
小结
Java 内建的 package 机制是为了避免 class 命名冲突;
JDK 的核心类使用 java.lang 包,编译器会自动导入;
JDK 的其它常用类定义在 java.util.*,java.math.*,java.text.*,……;
包名推荐使用倒置的域名,例如 org.apache。
作用域
public、protected、private 这些修饰符。在 Java 中,这些修饰符可以用来限定访问作用域。
public
定义为 public 的 class、interface 可以被其他任何类访问:
public class Hello {1 2 3 4 5 6 7 8 9 10 11 > 上面的 Hello 是 public,因此,可以被其他包的类访问: ```java package xyz; class Main { void foo() { // Main 可以访问 Hello Hello h = new Hello(); } }
定义为 public 的 field、method 可以被其他类访问,前提是首先有访问 class 的权限:
public class Hello {1 2 3 4 5 6 7 8 9 10 > 上面的 hi() 方法是 public,可以被其他类调用,前提是首先要能访问 Hello 类: ```java package xyz; class Main { void foo() { Hello h = new Hello(); h.hi(); } }
private
定义为 private 的 field、method 无法被其他类访问:
public class Hello {
public void hello() {
this.hi();
}
}1 2 3 4 5 6 7 8 9 10 11 12 > ** 实际上,确切地说,private 访问权限被限定在 class 的内部,而且与方法声明顺序无关。推荐把 private 方法放到后面,因为 public 方法定义了类对外提供的功能,阅读代码的时候,应该先关注 public 方法:** ```java package abc; public class Hello { public void hello() { this.hi(); } private void hi() { } }
由于 Java 支持嵌套类,如果一个类内部还定义了嵌套类,那么,嵌套类拥有访问 private 的权限:1 2 3 4 5 public class Main { public static void main (String[] args) { Inner i = new Inner (); i.hi(); }
// private 方法:
private static void hello() {
System.out.println("private hello!");
}
// 静态内部类:
static class Inner {
public void hi() {
Main.hello();
}
}
}1 2 3 4 5 6 7 8 9 10 11 12 > 定义在一个 `class` 内部的 `class` 称为嵌套类(nested class),Java 支持好几种嵌套类。经过自己测试: `static` 不能没有 ## protected > `protected` 作用于继承关系。定义为 `protected` 的字段和方法可以被子类访问,以及子类的子类: ```java package abc; public class Hello { // protected 方法: protected void hi() { } }
上面的 protected 方法可以被继承的类访问:
class Main extends Hello {1 2 3 4 5 6 7 8 9 10 11 ## package > 包作用域是指一个类允许访问同一个 `package` 的没有 `public`、`private` 修饰的 `class`,以及没有 `public`、`protected`、`private` 修饰的字段和方法。但是不允许包之外的类访问。 ```java package abc; // package 权限的类: class Hello { // package 权限的方法: void hi() { } }
只要在同一个包,就可以访问 package 权限的 class、field 和 method:
class Main {1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 > 注意,包名必须完全一致,包没有父子关系,`com.apache` 和 `com.apache.abc` 是不同的包 ## 局部变量 > 在方法内部定义的变量称为局部变量,局部变量作用域从变量声明处开始到对应的块结束。方法参数也是局部变量。 ```java package abc; public class Hello { void hi(String name) { // ① String s = name.toLowerCase(); // ② int len = s.length(); // ③ if (len < 10) { // ④ int p = 10 - len; // ⑤ for (int i=0; i<10; i++) { // ⑥ System.out.println(); // ⑦ } // ⑧ } // ⑨ } // ⑩ }
我们观察上面的 hi() 方法代码:
方法参数 name 是局部变量,它的作用域是整个方法,即 ①~⑩;
变量 s 的作用域是定义处到方法结束,即 ②~⑩;
变量 len 的作用域是定义处到方法结束,即 ③~⑩;
变量 p 的作用域是定义处到 if 块结束,即 ⑤~⑨;
变量 i 的作用域是 for 循环,即 ⑥~⑧。
final
final 与访问权限不冲突,它有很多作用。
用 final 修饰 class 可以阻止被继承:
// 无法被继承:1 2 3 4 5 6 7 8 9 10 > 2. 用 `final` 修饰 `method` 可以阻止被子类覆写: ```java package abc; public class Hello { // 无法被覆写: protected final void hi() { } }
用 final 修饰 field 可以阻止被重新赋值:
public class Hello {1 2 3 4 5 6 7 8 9 10 > 4. 用 final 修饰局部变量可以阻止被重新赋值: ```java package abc; public class Hello { protected void hi(final int t) { t = 1; // error! } }
最佳实践
如果不确定是否需要 public,就不声明为 public,即尽可能少地暴露对外的字段和方法。
把方法定义为 package 权限有助于测试,因为测试类和被测试类只要位于同一个 package,测试代码就可以访问被测试类的 package 权限方法。
一个. java 文件只能包含一个 public 类,但可以包含多个非 public 类。如果有 public 类,文件名必须和 public 类的名字相同。
小结
Java 内建的访问权限包括 public 、 protected 、 private 和 package 权限;
Java 在方法内部定义的变量是局部变量,局部变量的作用域从变量声明开始,到一个块结束;
final 修饰符不是访问权限,它可以修饰 class、field 和 method;
一个 .java 文件只能包含一个 public 类,但可以包含多个非 public 类。
关于修饰符的问题:
public:包内、包外(需要 import)都可以访问private:只有类的内部才可以访问protected:只有类、子类、子类的子类可以访问没有修饰符:只有包的内部能访问,包外不可以访问
内部类
通常情况下,我们把不同的类组织在不同的包下面,对于一个包下面的类来说,它们是在同一层次,没有父子关系:1 2 3 4 5 java.lang ├── Math ├── Runnable ├── String └── ...
Inner Class
如果一个类定义在另一个类的内部,这个类就是 Inner Class:1 2 3 4 5 class Outer { class Inner { } }
Outer 是一个普通类,而 Inner 是一个 Inner Class,它与普通类有个最大的不同,就是 Inner Class 的实例不能单独存在,必须依附于一个 Outer Class 的实例。示例代码如下:1 2 3 4 5 6 7 8 public class Main { public static void main (String[] args) { Outer outer = new Outer ("Nested" ); Outer.Inner inner = outer.new Inner (); inner.hello(); System.out.println(outer.age); } }
class Outer {
Outer(String name) {
this.name = name;
}
class Inner {
void hello() {
System.out.println("Hello," + Outer.this.name);
Outer.this.age =100; // 或者 age = 10;
}
}
}1 2 3 > 观察上述代码,要实例化一个 Inner,我们必须首先创建一个 Outer 的实例,然后,调用 Outer 实例的 new 来创建 Inner 实例: ```java Outer.Inner inner = outer.new Inner();
这是因为 Inner Class 除了有一个 this 指向它自己,还隐含地持有一个 Outer Class 实例,可以用 Outer.this 访问这个实例。所以,实例化一个 Inner Class 不能脱离 Outer 实例。
观察 Java 编译器编译后的. class 文件可以发现,Outer 类被编译为 Outer.class,而 Inner 类被编译为 Outer$Inner.class。
Anonymous Class (?)
还有一种定义 Inner Class 的方法,它不需要在 Outer Class 中明确地定义这个 Class,而是在方法内部,通过匿名类(Anonymous Class)来定义。示例代码如下:1 2 3 4 5 6 public class Main { public static void main (String[] args) { Outer outer = new Outer ("Nested" ); outer.asyncHello(); } }
class Outer {
Outer(String name) {
this.name = name;
}
void asyncHello() {
Runnable r = new Runnable() {
@Override
public void run() {
System.out.println("Hello," + Outer.this.name);
}
};
new Thread(r).start();
}
}1 2 3 4 5 > 观察 `asyncHello()` 方法,我们在方法内部实例化了一个 `Runnable`。`Runnable` 本身是接口,接口是不能实例化的,所以这里实际上是定义了一个实现了 `Runnable` 接口的匿名类,并且通过 new 实例化该匿名类,然后转型为 `Runnable`。在定义匿名类的时候就必须实例化它,定义匿名类的写法如下: ```java Runnable r = new Runnable() { // 实现必要的抽象方法... };
匿名类和 Inner Class 一样,可以访问 Outer Class 的 private 字段和方法。之所以我们要定义匿名类,是因为在这里我们通常不关心类名,比直接定义 Inner Class 可以少写很多代码。
除了接口外,匿名类也完全可以继承自普通类。观察以下代码:1 import java.util.HashMap;
public class Main {1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 > map1 是一个普通的 HashMap 实例,但 map2 是一个匿名类实例,只是该匿名类继承自 HashMap。map3 也是一个继承自 HashMap 的匿名类实例,并且添加了 static 代码块来初始化数据。观察编译输出可发现 Main$1.class 和 Main$2.class 两个匿名类文件。 ## Static Nested Class > 最后一种内部类和 Inner Class 类似,但是使用 static 修饰,称为静态内部类(Static Nested Class): ```java public class Main { public static void main(String[] args) { Outer.StaticNested sn = new Outer.StaticNested(); sn.hello(); } } class Outer { private static String NAME = "OUTER"; private String name; Outer(String name) { this.name = name; } static class StaticNested { void hello() { System.out.println("Hello," + Outer.NAME); } } }
用 static 修饰的内部类和 Inner Class 有很大的不同,它不再依附于 Outer 的实例,而是一个完全独立的类,因此无法引用 Outer.this,但它可以访问 Outer 的 private 静态字段和静态方法。如果把 StaticNested 移到 Outer 之外,就失去了访问 private 的权限。
但是在实例化 静态内部类 的时候,也会实例化一个 Outer
小结
Java 的内部类可分为 Inner Class、Anonymous Class 和 Static Nested Class 三种:
Inner Class 和 Anonymous Class 本质上是相同的,都必须依附于 Outer Class 的实例,即隐含地持有 Outer.this 实例,并拥有 Outer Class 的 private 访问权限;
Static Nested Class 是独立类,但拥有 Outer Class 的 private 访问权限。
补充
内部类就是在一个类的内部再定义一个类。比如:A类中定义一个B类,那么B类相对于A类来说就称为内部类,而A类相对于B类来说就是外部类了。
classpath 和 jar classpath
在 Java 中,我们经常听到 classpath 这个东西。网上有很多关于 “如何设置 classpath” 的文章,但大部分设置都不靠谱。到底什么是 classpath?classpath 是 JVM 用到的一个环境变量,它用来指示 JVM 如何搜索 class。
因为 Java 是编译型语言,源码文件是 .java,而编译后的 .class 文件才是真正可以被 JVM 执行的字节码。因此,JVM 需要知道,如果要加载一个 abc.xyz.Hello 的类,应该去哪搜索对应的 Hello.class 文件。classpath 就是一组目录的集合,它设置的搜索路径与操作系统相关。例如,在 Windows 系统上,用 ; 分隔,带空格的目录用 "" 括起来,可能长这样:1 C:\work\project1\bin;C:\shared;"D:\My Documents\project1\bin"
1 /usr/shared:/usr/local/bin:/home/liaoxuefeng/bin
classpath 是 .;C:\work\project1\bin;C:\shared,当 JVM 在加载 abc.xyz.Hello 这个类时,会依次查找:
<当前目录>\abc\xyz\Hello.classC:\work\project1\bin\abc\xyz\Hello.classC:\shared\abc\xyz\Hello.class
注意到 . 代表当前目录。如果 JVM 在某个路径下找到了对应的 class 文件,就不再往后继续搜索。如果所有路径下都没有找到,就报错。
classpath 的设定方法有两种:
在系统环境变量中设置 classpath 环境变量,不推荐;
在启动 JVM 时设置 classpath 变量,推荐。
我们强烈不推荐在系统环境变量中设置 classpath,那样会污染整个系统环境。在启动 JVM 时设置 classpath 才是推荐的做法。实际上就是给 java 命令传入 -classpath 或 -cp 参数:1 java -classpath .;C:\work\project1\bin;C:\shared abc.xyz.Hello
-cp 的简写:1 java -cp .;C:\work\project1\bin;C:\shared abc.xyz.Hello
-cp 参数,那么 JVM 默认的 classpath 为.,即当前目录:Hello.class。
在 IDE 中运行 Java 程序,IDE 自动传入的 - cp 参数是当前工程的 bin 目录和引入的 jar 包。class 中,会引用 Java 核心库的 class,例如,String、ArrayList 等。这些 class 应该上哪去找?
Note: 不要把任何 Java 核心库添加到 classpath 中!JVM 根本不依赖 classpath 加载核心库!
更好的做法是,不要设置 classpath!默认的当前目录. 对于绝大多数情况都够用了。1 2 3 4 C:\work └─ com └─ example └─ Hello.class
1 C:\work> java -cp . com.example.Hello
com.example.Hello,即实际搜索文件必须位于 com/example/Hello.class。如果指定的. class 文件不存在,或者目录结构和包名对不上,均会报错。
jar 包
如果有很多 .class 文件,散落在各层目录中,肯定不便于管理。如果能把目录打一个包,变成一个文件,就方便多了。classpath 中:1 java -cp ./hello.jar abc.xyz.Hello
那么问题来了:如何创建 jar 包?“压缩 (zipped) 文件夹”,就制作了一个 zip 文件。然后,把后缀从 .zip 改为 .jar,一个 jar 包就创建成功。
假设编译输出的目录结构是这样:1 2 3 4 5 6 7 8 9 package_sample └─ bin ├─ hong │ └─ Person.class │ ming │ └─ Person.class └─ mr └─ jun └─ Arrays.class
bin,而应该是 hong、ming、mr。如果在 Windows 的资源管理器中看,应该长这样:1 2 3 4 5 6 7 8 9 10 package_sample └─ bin └─ hello.zip ├─ hong │ └─ Person.class │ ming │ └─ Person.class └─ mr └─ jun └─ Arrays.class
1 2 3 4 5 6 7 8 9 10 11 package_sample └─ bin └─ hello.zip └─ bin ├─ hong │ └─ Person.class │ ming │ └─ Person.class └─ mr └─ jun └─ Arrays.class
hong.Person 必须按 hong/Person.class 存放,而不是 bin/hong/Person.class
jar 包还可以包含一个特殊的 /META-INF/MANIFEST.MF 文件,MANIFEST.MF 是纯文本,可以指定 Main-Class 和其它信息。JVM 会自动读取这个 MANIFEST.MF 文件,如果存在 Main-Class,我们就不必在命令行指定启动的类名,而是用更方便的命令:MANIFEST.MF 文件里配置 classpath 了。MANIFEST.MF 文件,再手动创建 zip 包。Java 社区提供了大量的开源构建工具,例如 Maven,可以非常方便地创建 jar 包。
小结
JVM 通过环境变量 classpath 决定搜索 class 的路径和顺序;
不推荐设置系统环境变量 classpath,始终建议通过 - cp 命令传入;
jar 包相当于目录,可以包含很多 .class 文件,方便下载和使用;
MANIFEST.MF 文件可以提供 jar 包的信息,如 Main-Class,这样可以直接运行 jar 包。
补充
idea 软件中 .class 在根目录的 out -> production 文件下个人理解 jar 包 : 就是将目录下的类打包,供其他人使用的,可以直接调用的压缩包文件
示例
我的目录1 2 3 4 5 6 7 8 9 IdeaTestProjects └─class2 └─unit10 ├─test1 │ └─Main.class │ └─Person.class │ └─test2 └─TestMain.class
IdeaTestProjects 打包 zip 文件,再将后缀名改为 jar, 然后运行如下命令1 java -cp IdeaTestProjects.jar class2.unit10.test1.Main
1 2 3 4 name: Qeuro age: 23 name: qeuro age: 23
模块
一个 class 类是一个 java 文件,后缀名为 .java,编译之后生成 .class 文件,而这个 .class 文件才真正可以被 JVM 执行的字节码。
定义
从 Java 9 开始,JDK 又引入了模块(Module)。.class 文件是 JVM 看到的最小可执行文件,而一个大型程序需要编写很多 Class,并生成一堆 .class 文件,很不便于管理,所以,jar 文件就是 .class 文件的容器。Java 9 之前,一个大型 Java 程序会生成自己的 jar 文件,同时引用依赖的第三方 jar 文件,而 JVM 自带的 Java 标准库,实际上也是以 jar 文件形式存放的,这个文件叫 rt.jar,一共有 60 多 M。app.jar 以外,还需要一堆第三方的 jar 包,运行一个 Java 程序,一般来说,命令行写这样:1 java -cp app.jar:a.jar:b.jar:c.jar com.liaoxuefeng.sample.Main
Note: JVM 自带的标准库 rt.jar 不要写到 classpath 中,写了反而会干扰 JVM 的正常运行。
如果漏写了某个运行时需要用到的 jar,那么在运行期极有可能抛出 ClassNotFoundException。
从 Java 9 开始引入的模块,主要是为了解决 “依赖” 这个问题。如果 a.jar 必须依赖另一个 b.jar 才能运行,那我们应该给 a.jar 加点说明啥的,让程序在编译和运行的时候能自动定位到 b.jar,这种自带 “依赖关系” 的 class 容器就是模块。rt.jar 分拆成了几十个模块,这些模块以 .jmod 扩展名标识,可以在 $JAVA_HOME/jmods 目录下找到它们:java.base.jmodjava.compiler.jmodjava.datatransfer.jmodjava.desktop.jmod...
这些 .jmod 文件每一个都是一个模块,模块名就是文件名。例如:模块 java.base 对应的文件就是 java.base.jmod。模块之间的依赖关系已经被写入到模块内的 module-info.class 文件了。所有的模块都直接或间接地依赖 java.base 模块,只有 java.base 模块不依赖任何模块,它可以被看作是 “根模块”,好比所有的类都是从 Object 直接或间接继承而来。
编写模块
如何编写模块呢?还是以具体的例子来说。首先,创建模块和原有的创建 Java 项目是完全一样的,以 oop-module 工程为例,它的目录结构如下:1 2 3 4 5 6 7 8 9 10 oop-module ├── bin ├── build.sh └── src ├── com │ └── itranswarp │ └── sample │ ├── Greeting.java │ └── Main.java └── module-info.java
bin 目录存放编译后的 .class 文件,src 目录存放源码,按包名的目录结构存放,仅仅在 src 目录下多了一个 module-info.java 这个文件,这就是模块的描述文件。在这个模块中,它长这样:1 2 3 4 module hello.world { requires java.base; requires java.xml; }
module 是关键字,后面的 hello.world 是模块的名称,它的命名规范与包一致。花括号的 requires xxx; 表示这个模块需要引用的其他模块名。除了 java.base 可以被自动引入外,这里我们引入了一个 java.xml 的模块。
当我们使用模块声明了依赖关系后,才能使用引入的模块。例如,Main.java 代码如下:1 package com.itranswarp.sample;
// 必须引入 java.xml 模块后才能使用其中的类:
public class Main {1 2 3 4 > 如果把 `requires java.xml;` 从 `module-info.java` 中去掉,编译将报错。可见,模块的重要作用就是声明依赖关系。 > 下面,我们用 JDK 提供的命令行工具来编译并创建模块。 > 首先,我们把工作目录切换到 `oop-module`,在当前目录下编译所有的 `.java` 文件,并存放到 `bin` 目录下,命令如下:
1 2 3 > 注意到 `src` 目录下的 `module-info.java` 被编译到 `bin` 目录下的 `module-info.class`。 > 下一步,我们需要把 `bin` 目录下的所有 `class` 文件先打包成 `jar`,在打包的时候,注意传入 `--main-class` 参数,让这个 `jar` 包能自己定位 `main` 方法所在的类:
1 > 现在我们就在当前目录下得到了 `hello.jar` 这个 `jar` 包,它和普通 `jar` 包并无区别,可以直接使用命令 `java -jar hello.jar` 来运行它。但是我们的目标是创建模块,所以,继续使用 `JDK` 自带的 jmod 命令把一个 `jar` 包转换成模块:
1 2 3 4 > 于是,在当前目录下我们又得到了 `hello.jmod` 这个模块文件,这就是最后打包出来的传说中的模块! ## 运行模块 > 要运行一个 jar,我们使用 `java -jar xxx.jar` 命令。要运行一个模块,我们只需要指定模块名。试试:
1 > 原因是 `.jmod` 不能被放入 `--module-path` 中。换成 `.jar` 就没问题了:
1 2 3 4 5 6 > 那我们辛辛苦苦创建的 hello.jmod 有什么用?** 答案是我们可以用它来打包 JRE。** ## 打包 JRE 前面讲了,为了支持模块化,Java 9 首先带头把自己的一个巨大无比的 rt.jar 拆成了几十个. jmod 模块,原因就是,运行 Java 程序的时候,实际上我们用到的 JDK 模块,并没有那么多。不需要的模块,完全可以删除。 过去发布一个 Java 应用程序,要运行它,必须下载一个完整的 JRE,再运行 jar 包。而完整的 JRE 块头很大,有 `100+M`。怎么给 JRE 瘦身呢? 现在,JRE 自身的标准库已经分拆成了模块,只需要带上程序用到的模块,其他的模块就可以被裁剪掉。怎么裁剪 JRE 呢?并不是说把系统安装的 JRE 给删掉部分模块,而是 “复制” 一份 JRE,但只带上用到的模块。为此,JDK 提供了 `jlink` 命令来干这件事。命令如下:
1 2 我们在 `--module-path` 参数指定了我们自己的模块 `hello.jmod`,然后,在 `--add-modules` 参数中指定了我们用到的 3 个模块 `java.base`、`java.xml` 和 `hello.world`,用 `,` 分隔。最后,在 `--output` 参数指定输出目录。 现在,在当前目录下,我们可以找到 jre 目录,这是一个完整的并且带有我们自己 `hello.jmod` 模块的 JRE。试试直接运行这个 JRE:
1 2 3 4 5 6 7 要分发我们自己的 `Java` 应用程序,只需要把这个 `jre` 目录打个包给对方发过去,对方直接运行上述命令即可,既不用下载安装 `JDK`,也不用知道如何配置我们自己的模块,极大地方便了分发和部署。 ## 访问权限 前面我们讲过,`Java` 的 `class` 访问权限分为 `public`、`protected`、`private` 和默认的包访问权限。引入模块后,这些访问权限的规则就要稍微做些调整。 确切地说,`class` 的这些访问权限只在一个模块内有效,模块和模块之间,例如,`a` 模块要访问 `b` 模块的某个 `class`,必要条件是 `b` 模块明确地导出了可以访问的包。 举个例子:我们编写的模块 `hello.world` 用到了模块 `java.xml` 的一个类 `javax.xml.XMLConstants`,我们之所以能直接使用这个类,是因为模块 `java.xml` 的 `module-info.java` 中声明了若干导出:
1 只有它声明的导出的包,外部代码才被允许访问。换句话说,如果外部代码想要访问我们的 `hello.world` 模块中的 `com.itranswarp.sample.Greeting` 类,我们必须将其导出:
requires java.base;
requires java.xml;
}