66. Flask 部署上线
购买一个服务器,如在:阿里云、腾讯云上买等(阿里云有学生版);
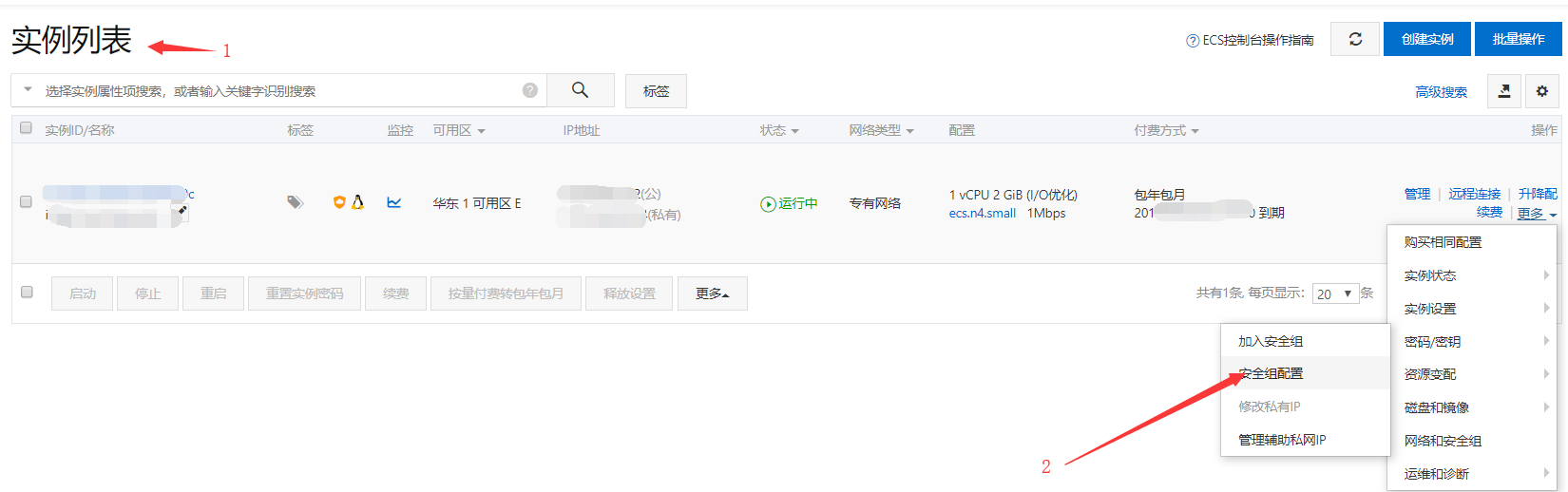
将服务器添加安全组
- 进入实例列表,点击
更多-网络和安全组-安全组配置- ``,如图所示:![]()
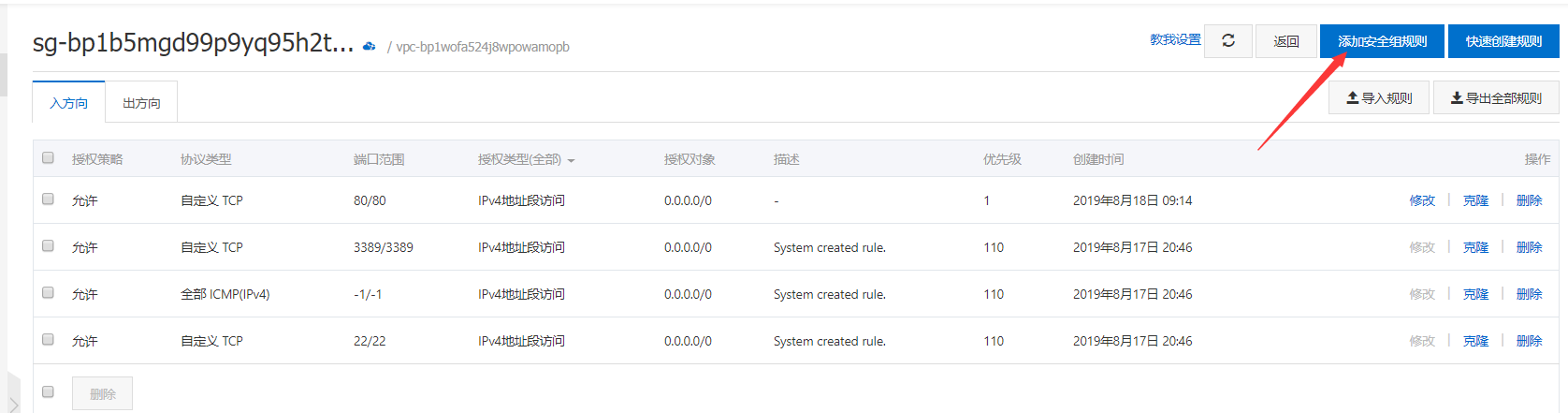
- 进入
配置规则:![]()
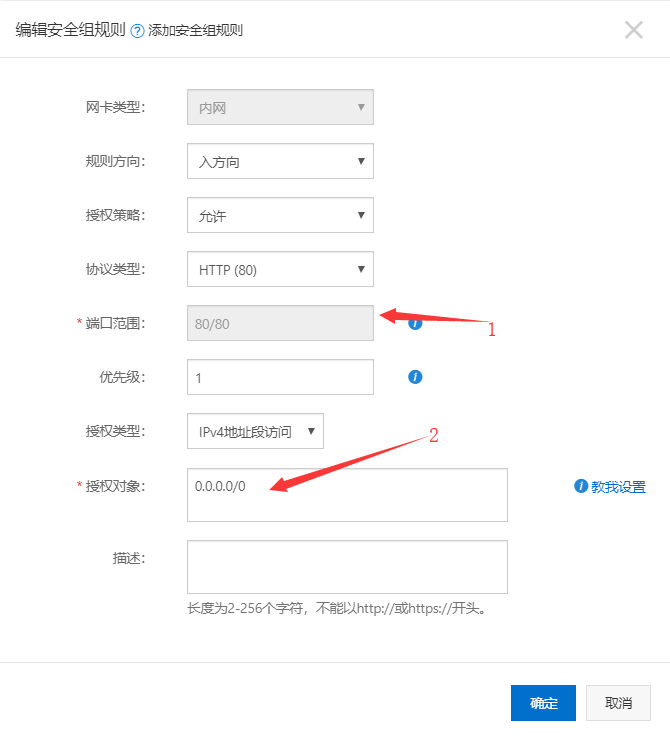
- 选择
添加安全组规则:![]()
- 将所指的地方,一模一样的填入到你的规则下
![]()
- 进入实例列表,点击

- 使用
xshell连接- 具体使用,百度
- 使用
cmd连接- 连接实例:
ssh demo@123.123.123.123 - 其中:
demo为用户名,123.123.123.123为公网地址
- 连接实例:
更新系统可安装的包文件,并对课升级的包,进行升级:
1
2apt update
apt upgrade创建用户:
adduser lqr为用户赋予
root权限:usermod -aG sudo lqr切换用户:
su lqrpython3 安装
pip、dev:sudo apt install python3-dev python3-pip查看
pip3的版本:pip3 --version为
pip、pip3设置镜像:1
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
全局安装
pipenv:sudo -H pip3 install pipenv【注意】:一定要全局安装,哪怕是使用
pip3 install pipenv,也要用上面的命令装一次重新更新一遍:
1
2sudo apt update
sudo apt upgrade设置防火墙,并更新规则:
1
2
3
4sudo ufw allow 22
sudo ufw allow 80
sudo ufw allow 443
sudo ufw enable // 更新规则查看防火墙状态:
sudo ufw status将仓库的目录下载到本地,实例以
MMCs为例,即:lqr目录下有MMCs文件夹进入文件夹,并创建虚拟环境
1
2cd MMCs
pipenv install创建
.env:nano .env(可以直接复制)1
2FLASK_ENV=production
FALSK_CONFIG=production设置pipenv的镜像:
- 查看 Pipfile :
cat Pipfile1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17[[source]]
url = "https://pypi.org/simple"
verify_ssl = true
name = "pypi"
[packages]
flask = "*"
requests = "*"
wtforms = "*"
flask-sqlalchemy = "*"
cymysql = "*"
flask-login = "*"
[dev-packages]
[requires]
python_version = "3.7" - 将第2行:
url = "https://pypi.org/simple"替换成:url = "https://pypi.tuna.tsinghua.edu.cn/simple/"(这里的网址,可以替换成其他镜像)
- 查看 Pipfile :
进入shell,并安装
--dev、uwsgi(在MMCs文件夹下进行):1
2
3pipenv shell
pipenv install --dev
pipenv install uwsgi接着执行以下命令
1
2
3
4flask init // 如果已经初始化过,这里改成 flask init --drop
flask forge
flask translate compile
flask run如果出现类似下面的内容,说明配置的应该是正确的
1
2
3
4
5* Environment: development
* Debug mode:on
* Debugger is active!
* Debugger PIN: 202-005-064
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)然后,按
CTRL+C结束,进行下一步使用 Gunicorn 运行程序
- 安装
pipenv install gunicorn - 设置防火墙:
sudo ufw allow 8000 - 更新防火墙规则:
sudo ufw enable - 运行程序:
gunicorn --workers=4 wsgi:app - 按
CTRL+C结束,进行下一步
- 安装
键入:
exit,以退出 MMCs使用
nginx- 安装 nginx :
sudo apt install nginx - 可以访问你的
公网ip(例如本案例中:123.123.123.123),可以看到welcome nginx的界面 - 删除 default :
sudo rm /etc/nginx/sites-enabled/default - 创建同项目文件夹名称的文件: 添加以下内容:
1
sudo nano /etc/nginx/sites-enabled/MMCs
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16server {
listen 80 default_server;
server_name _;
access_log /var/log/nginx/access.log;
error_log /var/log/nginx/error.log;
location / {
include uwsgi_params;
uwsgi_pass 127.0.0.1:3031;
}
location /static {
alias /home/lqr/MMCs/MMCs/static/;
expires 7d;
}
} - 测试nginx语法的正确性:
sudo nginx -t,如果有下面的内容说明正确:1
2nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful - 重启 nginx:
sudo service nginx restart - 设置 nginx的转发目标地址:
gunicorn -w 4 wsgi:app
- 安装 nginx :
使用 Supervisor 管理进程
- 安装:
sudo apt install supervisor - 创建 MMCs.conf文件: 写入以下配置(自己按照情况改变):
1
sudo nano /etc/supervisor/conf.d/MMCs.conf
1
2
3
4
5
6
7
8[program:MMCs]
command=pipenv run uwsgi --socket 127.0.0.1:3031 --wsgi-file wsgi.py --callable app --processes 4 --threads 2 --stats 127.0.0.1:9191
directory=/home/lqr/MMCs
user=lqr
autostart=true
autorestart=true
stopasgroup=true
killasgroup=true - 配置 supervisord.conf
- 在 [supervisord] 节下添加下面这行定义
1
environment=LC_ALL='en_US.UTF-8',LANG='en_US.UTF-8'
- 在末尾添加
1
2
3
4[inet_http_server]
port=*:9001
username=lqr
password=lqr - 重启
supervisor服务:sudo service supervisor restart - 查看状态和进行相关操作:
sudo supervisorctl
- 在 [supervisord] 节下添加下面这行定义
- 安装:
- 安装
unzip:sudo apt install unzip - 将zip解压到
temp文件夹中1
2mkdir temp
unzip -d temp temp.zip【注意】:命令需要在当前文件夹中
- 如果pip3 出现如下错误那么,修改
1
2
3
4Traceback (most recent call last):
File "/usr/bin/pip", line 9, in <module>
from pip import main
ImportError: cannot import name 'main'/usr/bin/pip3:1
sudo nano /usr/bin/pip3
将
from pip import main修改为from pip._internal import main,即可 - 如果使用
pipenv install --dev安装依赖,出现安装超时:ReadTimeoutError,那么将.env的文件添加PIPENV_TIMEOUT=3600 - 如果想重新初始化或者更改了某些文件,执行下面的命令
1
2
3
4flask init --drop
flask forge
flask translate compile
flask run - nginx上传默认1m,因此,需要更改一下:
- 打开nginx配置文件 nginx.conf, 路径一般是:/etc/nginx/nginx.conf
- 在http{}段中加入 client_max_body_size 20m; 20m为允许最大上传的大小
- 保存后重启nginx,问题解决。
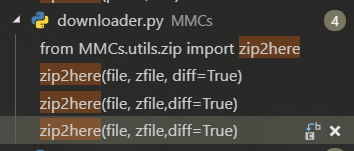
- 文件下载不了:将
diff更改为true,见下图:![]()
[错误日志]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28[2019-08-20 11:24:30,814] - MMCs - 60.2.111.59 requested http://47.98.142.112/admin/score/download/teacher
ERROR in app: Exception on /admin/score/download/teacher [GET]
Traceback (most recent call last):
File "/home/lqr/.local/share/virtualenvs/MMCs-SswGTqqS/lib/python3.6/site-packages/flask/app.py", line 2446, in wsgi_app
response = self.full_dispatch_request()
File "/home/lqr/.local/share/virtualenvs/MMCs-SswGTqqS/lib/python3.6/site-packages/flask/app.py", line 1951, in full_dispatch_request
rv = self.handle_user_exception(e)
File "/home/lqr/.local/share/virtualenvs/MMCs-SswGTqqS/lib/python3.6/site-packages/flask/app.py", line 1820, in handle_user_exception
reraise(exc_type, exc_value, tb)
File "/home/lqr/.local/share/virtualenvs/MMCs-SswGTqqS/lib/python3.6/site-packages/flask/_compat.py", line 39, in reraise
raise value
File "/home/lqr/.local/share/virtualenvs/MMCs-SswGTqqS/lib/python3.6/site-packages/flask/app.py", line 1949, in full_dispatch_request
rv = self.dispatch_request()
File "/home/lqr/.local/share/virtualenvs/MMCs-SswGTqqS/lib/python3.6/site-packages/flask/app.py", line 1935, in dispatch_request
return self.view_functions[rule.endpoint](**req.view_args)
File "/home/lqr/.local/share/virtualenvs/MMCs-SswGTqqS/lib/python3.6/site-packages/flask_login/utils.py", line 299, in decorated_view
return func(*args, **kwargs)
File "./MMCs/blueprints/admin.py", line 286, in download_teacher
zfile = gen_teacher_result(com.id)
File "./MMCs/downloader.py", line 46, in gen_teacher_result
zip2here(file, zfile)
File "./MMCs/utils/zip.py", line 22, in zip2here
z.write(input_path, file)
File "/usr/lib/python3.6/zipfile.py", line 1617, in write
zinfo = ZipInfo.from_file(filename, arcname)
File "/usr/lib/python3.6/zipfile.py", line 507, in from_file
st = os.stat(filename)
FileNotFoundError: [Errno 2] No such file or directory: 'h'